Understanding the UMH datamodel
In this lecture, you will understand the three parts of the UMH datamodel: events, database and API. Additionally, we will explain how you can append the UMH datamodel to introduce your own use-cases such as the digital shadow.
These are the core pillars of designing the architecture:
- It MUST work for IT and OT. This means that it needs to leverage IT best practices in terms of schemas, database modelling and APIs, while making the integration for OT people as simple as possible.
- The datamodel MUST stretch and be consistent throughout all three parts: information coming into the system as events must be stored in the database and retrieved via the API using the same information models.
- It MUST incorporate existing standards and best-practices in IT and OT whenever possible. Examples of widespread standards and best-practices are ISA95, HTTP/REST and MQTT. Deviating from those standards MUST be the exception.
- It MUST be as simple as possible to allow for an easy integration. Abstractions SHOULD be prevented.
- It MUST support multiple use-cases. We will detail it out for two of them (Historian and Analytics) and suggest an example "custom" use-case for Digital Shadow.
This lecture is designed to give you an overview and help you with understanding the reasons behind those architectural decisions. For the latest reference, please check out umh.docs.umh.app instead.
Events
We will start with the events section.
Introduction
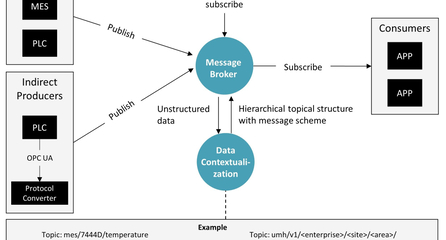
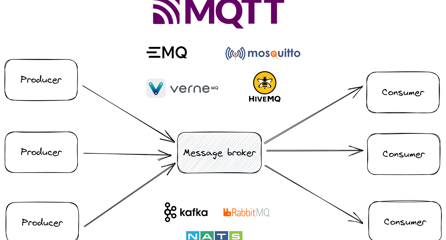
An application consists always out of multiple building blocks. To connect those building blocks, one can either exchange data between them through databases, through service calls (such as REST), or through a message broker. Events are messages send to the Unified Namespace, which in the case of UMH consists out of MQTT and Kafka. In the United Manufacturing Hub, each single piece of information / “message” / “event” is sent through a message broker, which is also called the Unified Namespace.
Why we have two message brokers MQTT and Kafka? Easy: to combine the advanatges and mitigate their own individual shortcomings. MQTT allows for easy integration with shopfloor equipment and legacy stuff as it is an easy protocol. It also allows for real-time notifications and can handle millions of devices in your factory. MQTT struggles however with properly buffering and processing those messages. By using Kafka, you can efficiently at-least-once process each message, ensuring that each message arrives at-least-once (1 or more times). By looking into the Kafka logs, you can always be aware of the last messages that have been sent to a topic. This allows you to replay certain scenarios for troubleshooting or testing purposes. More information on the journey can be found here: https://learn.umh.app/blog/tools-techniques-for-scalable-data-processing-in-industrial-iot/
A note about Sparkplug-B: There is a standard out there that describes a possible payload and topic structure and that is Sparkplug-B. However, it focuses only on one use-case "Device Management" and is incompatible with an ISA95 model. Furthermore, it is based on ProtoBuf, which is easy for an IT person to integrate, but might overcomplicate it for people in OT. In Manufacturing most devices are connected via Ethernet cables, so the bandwidth savings compared to the increased complexity are not worth it.
Topic Structure
We use an ISA95 compliant topic structure:
umh/v1/enterprise/site/area/productionLine/workCell/originID/_usecase/tag
All topic names are case-insensitive and only allow as characters a-z, A-Z, 0-9 and - and _. Characters such as ., +, # or / are reserved characters in either MQTT or Kafka, so they cannot be used in either of them.
umh/v1 allows versioning of the datamodel and changes in the future. It is mandatory.
enterprise, site, area, productionLine, and workCell have the same meaning as in the ISA95 model. Mandatory is only the enterprise value, the rest are optional. Omitting the others can be used in cases where you want to model devices or information outside the traditional ISA95 model, e.g., a room temperature sensor for a specific area.
originID allows to specify the origin of the information. This could be a unique device ID such as a serial number or MAC address. It could also be the name of a docker container extracting information from an MES. When multiple origins in the ID we recommend separating them with underscores. Examples of originIDs: E588974, 00-80-41-ae-fd-7e, VM241_nodered_mes. This value is mandatory. It SHOULD be enforced via ACLs that a producer can only send messages into a topic with this originID.
_use-case MUST begin with an underscore (reasons further below) and indicates the use-case that is modelled here. By default, the UMH uses two of them:
_historian_analytics_local
By default, messages coming in into the first two use-cases _historian and _analytics MUST follow the UMH payload schema (see further below) and will be discarded if they do not. When using the UMH, only messages from those two topics will be stored in a database, except when you define a new use-case (see further below)
The third one, _local, SHOULD be used when a message should stay local to the message broker and not be parsed, checked for any schema or processed by any default microservice (incl. the one bridging MQTT and Kafka). _local can be used in cases where you cannot control the data format of the messages (e.g., from external systems), but the topic structure and want to push it into the ISA95 data format. Typically, those messages are then transformed to the UMH payload schema and then send to the "proper" topic back.
Theoretically, any other name can be used as well as long as it starts with an underscore. This can be used to add your own use-case to it and we will do it in a separate chapter for the use-case _digitalshadow. Messages will be bridged across MQTT and Kafka, but not checked for any schema compatibility. The UMH will include a feature in the future to add your own schemas to it.
tag is optional, but in general recommended and for the default use-case _analytics even mandatory. It can be used to specify a certain message type or to create topic groups. See also topic & payload structure of those use-cases for examples.
Note regarding the underscore: because one can omit elements of the ISA95 modell (such as workCell when modeling the entire production line), it can make parsing and detecting whether the current part of the topic is now a workCell or a use-case difficult. To reduce complexity when parsing and increase resiliency, the use-case needs to always start with an underscore.
Payload Schema
The payload MUST adhere to the payload schema for the two use-cases _historian and _analytics. The payload schema in the UMH datamodel is based on the _usecase and tag:
_historian
This should be used whenever you want to use the Historian Feature of the UMH (https://umh.docs.umh.app/docs/features/historian/), which provides reliable data storage and analysis for your manufacturing data.
The payload is a JSON with at least two keys:
timestamp_msas int64 with the Unix timestamp in milliseconds upon message creation- at least one additional key as either int64 or float64, e.g.,
"temperature": 56.3
You have three options to group together tags, e.g., to put them into a standardized information model:
- Using underscores in the key name, such as
spindle_axis_x. It will show up the tagxin the groupaxiswhich is a sub-group ofspindle. - If you use a
taginside the topic, it will be put before the key name. To use multiple groups, you can use the topic delimiter (/for MQTT and.for Kafka). - Combine 1 and 2. If you send it into a topic called
.../_historian/spindle/axisand call the key namex_pos, a tagposwill be stored in the groupxwhich is a sub-group ofaxiswhich is again a sub-group ofspindle
Example 1: if you send a message into the topic umh/v1/dcc/aachen/shopfloor/wristband/warping/_historian/spindle/axis with the following payload:
{
"timestamp_ms": 1680698839098,
"x_pos": 52.2,
"x_speed": 2,
"y_pos": -56.4,
"y_speed": 1.5
}You will save
- for the equipment
warpingin thewristbandproduction line located in the areashopfloorin a site calledaachenfor the enterprisedcc - four tags, with two tags called
posandspeedin the groups / sub-groupsspindle_axis_xas well as two tags with the same name in the groups / sub-groupsspindle_axis_y - for the Unix timestamp
1680698839098
into the database, which can then retrieved from the API. More information about how it is stored and how it can be retrieved in the subsequent chapters.
Example 2: if you send a message into the topic umh/v1/dcc/aachen/_historian with the following payload:
{
"timestamp_ms": 1680698839098,
"temperature": 18.2
}You will save
- for the site called
aachenbelonging to the enterprisedcc - one tag called
temperature - for the Unix timestamp
1680698839098
into the database, which can then retrieved from the API.
If a message does not comply with that topic and message schema, it will be discarded and logged. The mqtt-to-kafka bridge will output a warning message into its logs. kafka-to-postgresql will output a warning and additional put the message into a separate "putback queue". More information on this behaviour can be found in the documentation
_analytics
This should be used when you want to leverage the Analytics Feature of the UMH (https://umh.docs.umh.app/docs/features/analytics/) to create, for example, production dashboards containing automated calculated OEEs, drill-downs into stop-reasons, order overviews, machine states and similar.
The payload is always a JSON, but with a different payload schema depending on the tag that has been specified.
Other use-cases
The payload for the other use-cases SHOULD adhere to a JSON containing the timestamp as UNIX Millis with the key "timestamp_ms".