


Note: This blog article is based on the presentation given by Jeremy Theocharis at Cloudland 2024 and was written together with Denis Gontcharov
Connecting a USB stick to the "cloud" seems to be a stupid thing to do. Yet, it is something that we must do if we want to increase the efficiency of our world's production and therefore reduce CO2. Nearly every factory in the world—whether they're churning out cars, energy, shampoo, or just about anything else—still operates on technology from the 90s. There’s a good reason for this reliance on seemingly outdated tech, but it does create a significant hurdle for integrating with today's advanced cloud environments.
First off, we’ll break down the system architecture of a typical manufacturing plant and draw parallels to a distributed system. After unpacking how these systems work, we’ll dive into some of the major challenges of connecting manufacturing operations to the cloud—like, exaggeratedly speaking, figuring out how to get a USB stick full of critical data up into the cloud. Finally, the United Manufacturing Hub (UMH) is introduced as an open-source solution to these challenges that cleverly leverages cloud-native IT technologies on the manufacturing plant's edge.
Traditional automation is a highly distributed system
In essence, manufacturing is about controlling physical processes in real-time to produce goods: from car doors to beverage cans. Whether it's the automotive or food processing industry or aerospace, the objective is always to manufacture something. Developing the software that controls these production processes is the responsibility of Operational Technology (OT). As will later be seen, OT often stands in stark contrast with IT.
Industrial Automation is about controlling real-time processes
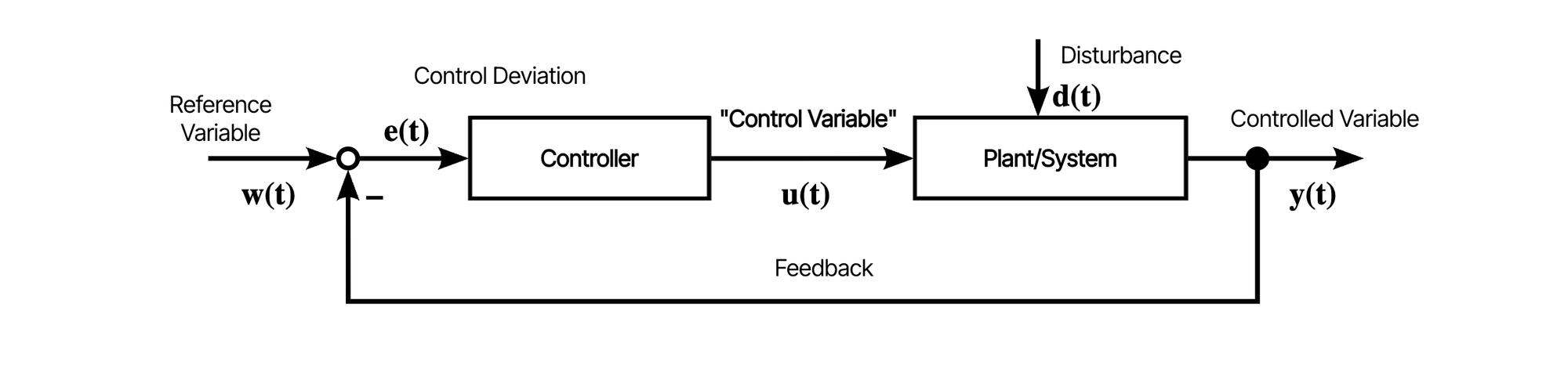
What all production processes have in common is that they are all steered by so-called control loops, a concept from control engineering.
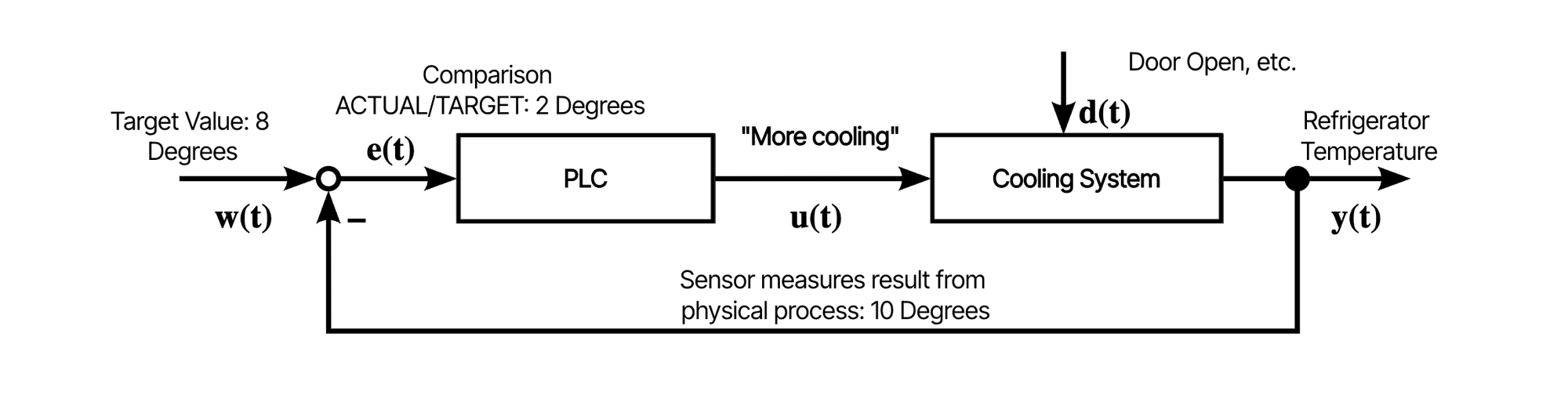
Now, a simple example of a control loop temperature control system of a fridge: In the image below, there's a controller and a cooling system. A temperature sensor measures the current temperature. This measured output is compared to a reference and the measured error is communicated to the controller. The controller then executes its control algorithm and calculates the input for the system. The sensor re-measures the system output and the cycle repeats itself.
Deterministic & real-time programming

The controller in these control loops is, in industrial settings, called a Programmable Logic Controller (PLC). A PLC can be thought of as an "industrial computer" optimized for deterministic programming of machines. This means the PLC executes its control tasks in a predictable and repeatable manner. It doesn't require a monitor, keyboard or any other device to work properly.
Programs that run on a PLC have two special requirements compared to your average IT programs: First, they require real-time processing (from nano-seconds to milliseconds precision). For example, control algorithms for CNC-drilling machines require millisecond precision so that the machine can react quickly to certain vibrations to prevent potential damage. Second, the processing needs to be deterministic. This means that the execution of the continuous cycles must happen with a constant processing time. Otherwise, the control algorithms would not work and it could happen that the machine vibrates out of control.
Remarkably, the programming of such control systems is not done by traditional programmers, as they are known in IT. Instead, programs in OT are developed by process engineers, electrical engineers or automation engineers, as only they have the required process knowledge to develop these algorithms.
Therefore, the systems that are programmed differ wildly from IT systems. Although, technically speaking, a computer (the PLC) is programmed, this computer has no common operating system. It's neither an traditional embedded system that can be programmed with C, C++ or Rust. You could "hack" into the PLC and could probably uncover the operating system or deploy your own applications, but that would (likely) void the warranty and legally required certifications.
These systems have to be very minimal by design because safety, aka determinism and real-time, is the main concern. Therefore programming languages like C or Rust can't be used, they are too difficult to get them safely to run for an electrician. Instead, specific programming languages like "ladder logic", contact plans, structured text are used instead. The core of them is standardized, but in reality every vendor pushing its own language style, which can only work with their IDE.

Multiple connected control loops form a distributed system
The individual control loops are connected via a fieldbus along with other components such as Human Machine Interfaces (HMI) and other machines. Here the parallel with IT is drawn: this combining of multiple individual systems over a real-time common interface can be likened to a distributed system.
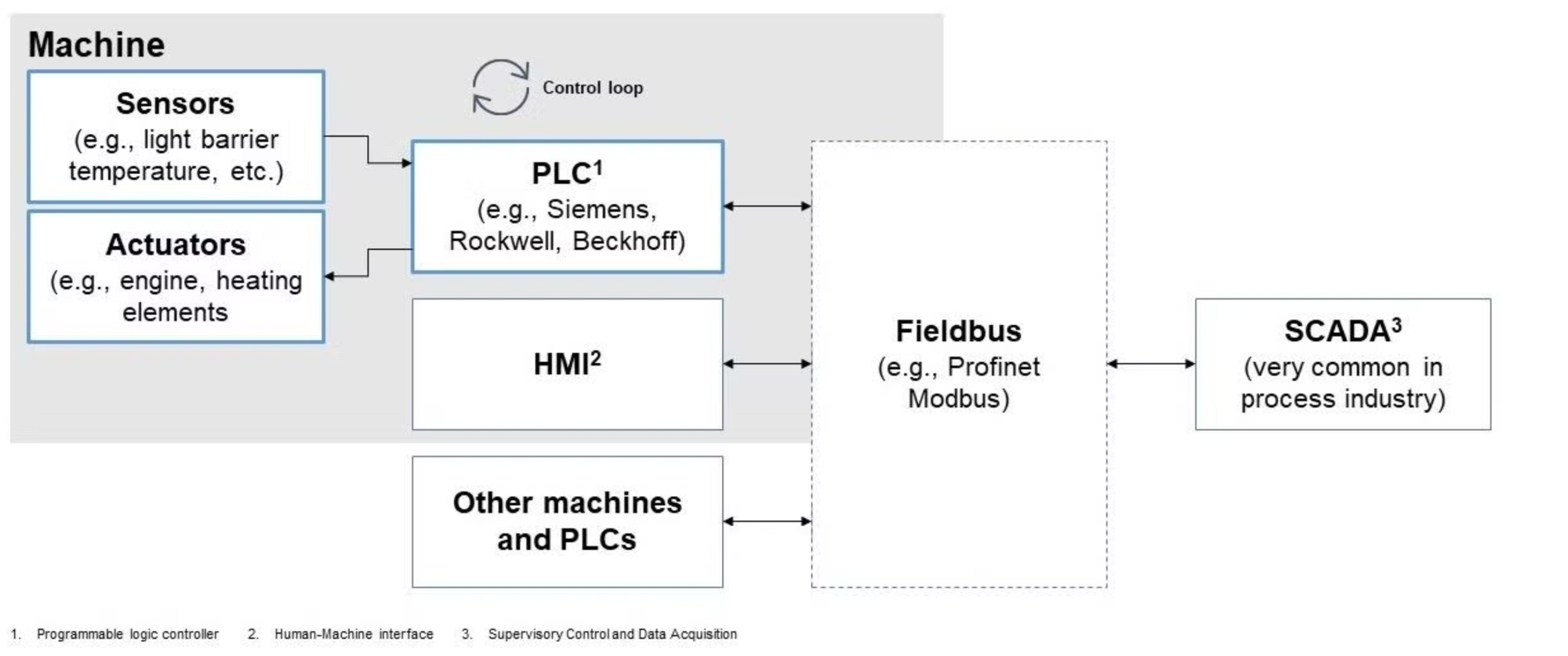
Unfortunately, this also means that manufacturing inherits all of the problems of distributed systems: loss of messages, inconsistency, availability, CAP-theorem, etc. For example, what happens if messages are lost? How to guarantee consistency if an error occurred somewhere and a node goes down?
Current approaches of handling the integration with IT
To manage the complexity of this "distributed system", a standard was developed and documented in the ISA-95 specification known as the automation pyramid.
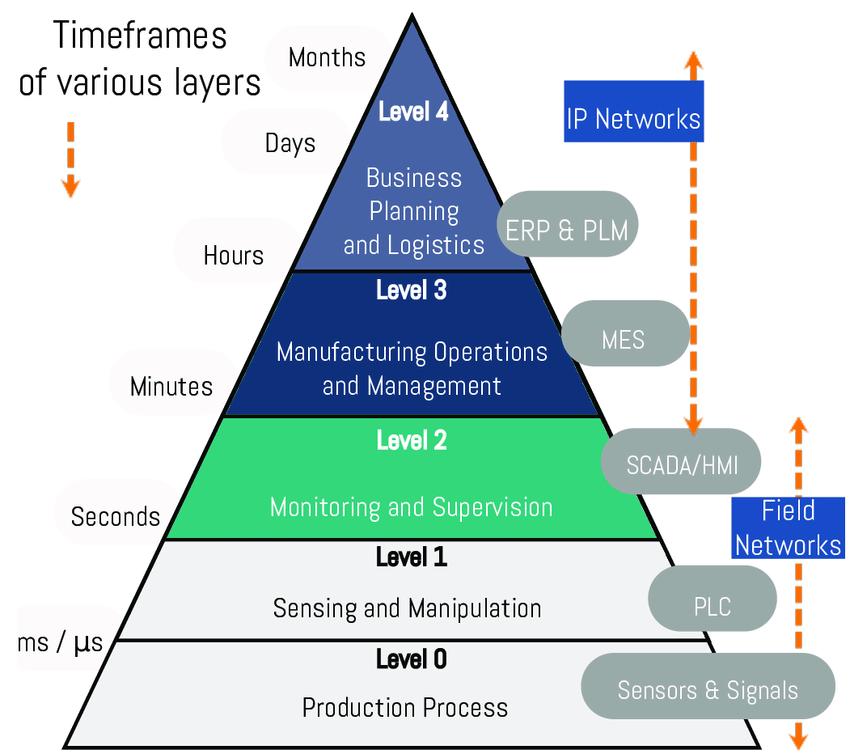
In a nutshell, the automation pyramid organizes the software systems in a manufacturing plant into a hierarchy of layers, from OT (bottom layers) to IT (top layers). In the middle layers (e.g. SCADA and MES), the responsibilities of IT and OT overlap. The image below also highlights the different time scales in which IT and OT operate: from days to milliseconds respectively. Purchasing decisions are made with a frequency of days and weeks, whereas steering a robot arm needs a 20 millisecond frequency.
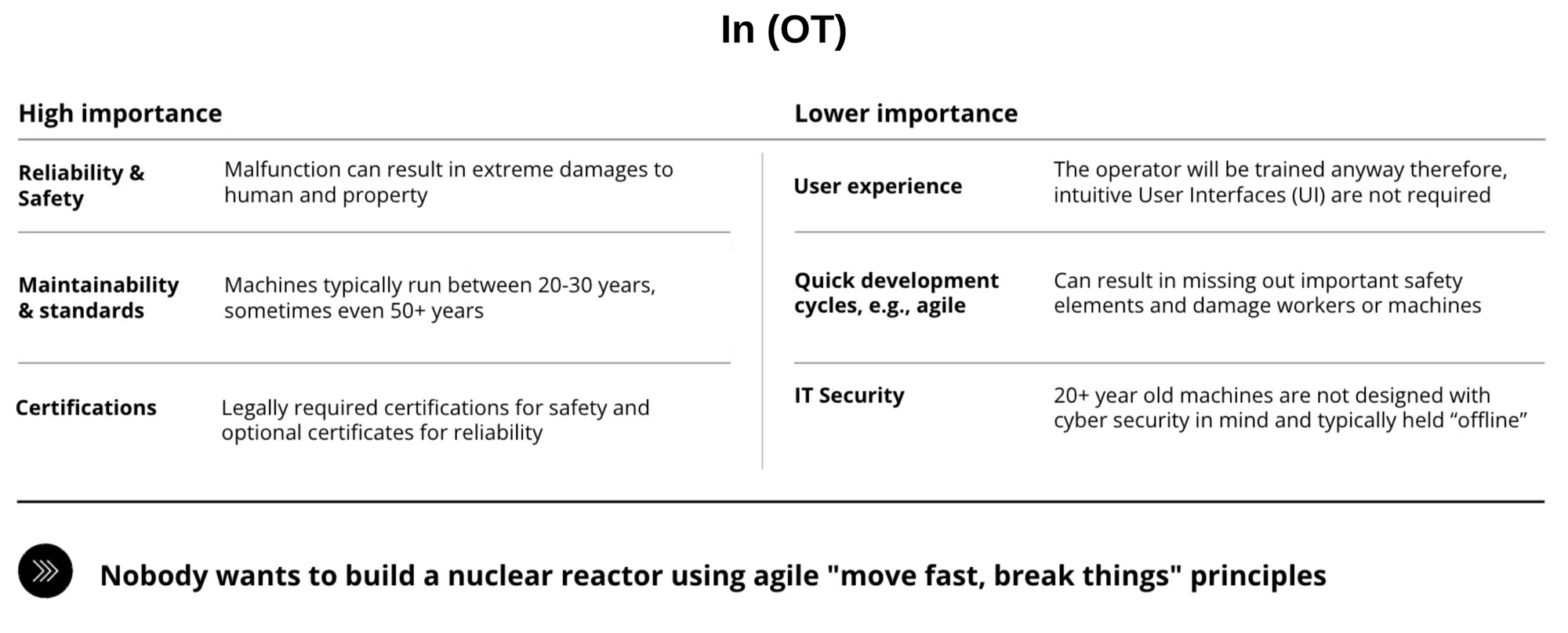
OT places a high importance on reliability and safety, as malfunctions can cause damage to people and property. Maintainability and standards are paramount as machines run between twenty and thirty years, and sometimes longer. Finally, most equipment and programs must be certified by law, proving their reliability and safety.
OT places a low importance on user experience because operators are trained and required to use the provided tools, so a "pretty" interface is not required. Quick development cycles are unwanted: nobody wants to build a nuclear reactor using agile "move fast, break things" principles. Finally, OT systems traditionally have little to no concern for IT security because they are typically not connected to an outside network.
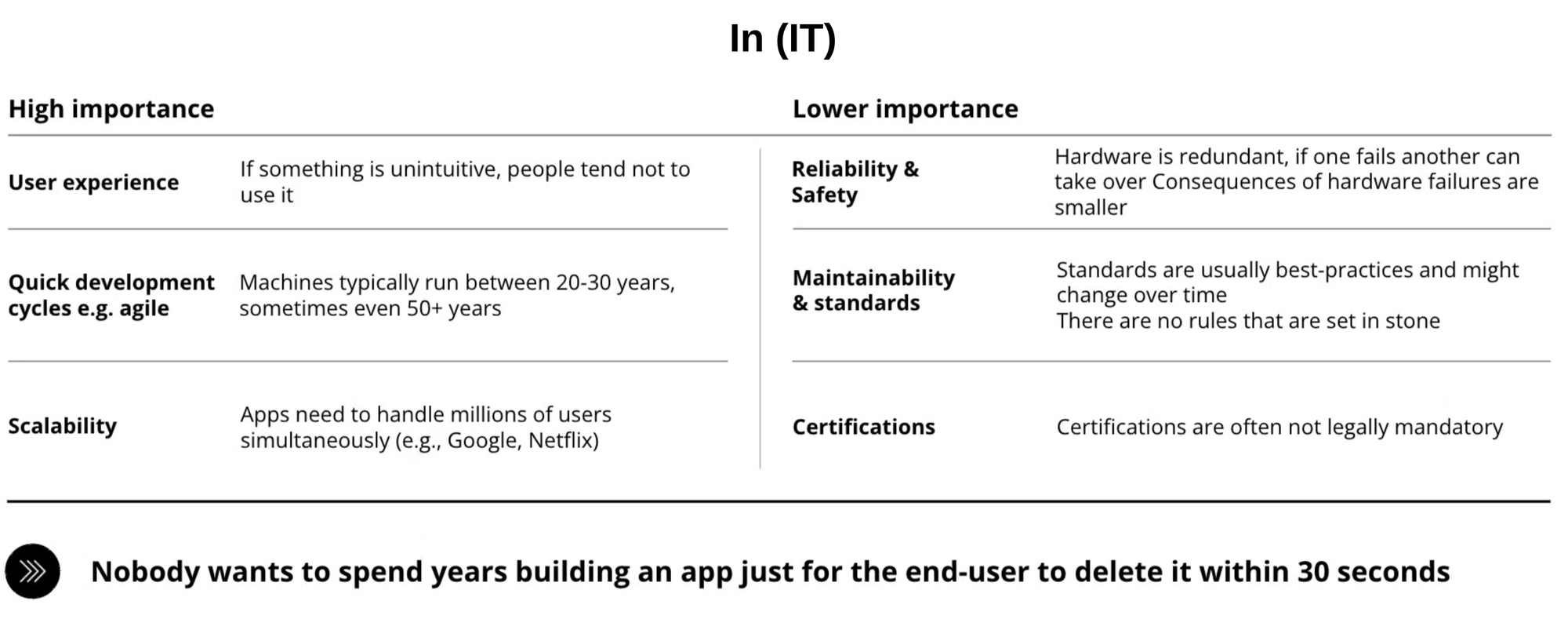
Unlike OT, IT places a high importance on a good user experience. If the solution is unintuitive, people won't use it. Quick development cycles are important as users require frequent changes fast. Finally, scalability can be important when apps need to handle millions of users, e.g. Netflix.
Conversely, IT places low importance to concepts like reliability because IT hardware is redundant. There is a weaker focus on maintainability and standardizations. The standards in IT are rather best-practices instead of rules that are set in stone. Finally, only in rare cases do IT systems require official certifications.
Summary
As we have seen, the traditional automation system operates as a distributed network, carefully structured within the layers of the automation pyramid. This architecture ensures that each component functions reliably and securely within its designated role, from the production floor up to the operational monitoring systems. While this setup excels in reliability and operational integrity, it poses significant challenges when considering integration with newer, more flexible technologies, such as the "cloud"
The next chapter explores why connecting traditional automation to the cloud is far more complex than anticipated, digging into the technical, security, and cultural hurdles that must be navigated.
Connecting the traditional automation to the "cloud" is more difficult than expected
With the advent of the cloud, the typical IT approach involves rebuilding IT workflows with cloud-native services of typical public cloud providers like AWS, Azure or GCP. These services rely heavily on containerization. The orchestration of containers in a modern IT landscape is typically performed by Kubernetes, either self-managed or used as a service by the cloud provider. This is a huge contrast to OT.
Challenges
The differences between IT and OT bring about a number of challenges for this cloud-native approach. Especially the OT systems, i.e. the lower levels of the automation pyramid, make cloud integration particularly difficult.
Challenge 1: Handling Security
IT goes more into the direction of a zero-trust-security approach whereas OT never intended its systems to be connected externally. Therefore, connecting an OT system to an outside network raises a lot of security risks. Just take a look at the current CISA advisories and you will find every week at least one critical security vulnerability of a major PLC vendor.

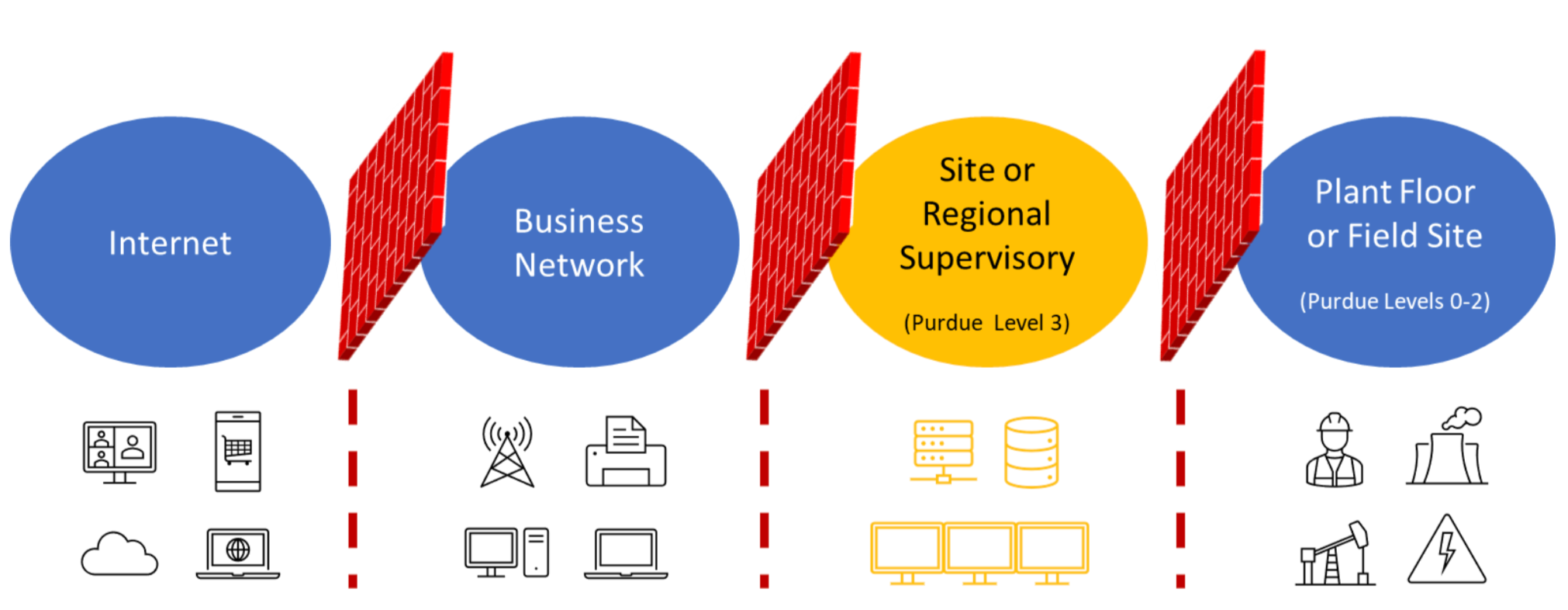
To counter this, the traditional solution in OT is to set up one or in the Purdue Enterprise Reference Architecture (PERA) even multiple demilitarized zones separated by firewalls. In the image below, the various layers of the automation pyramid (also called Purdue model) are separated by such firewalls. Unfortunately, these barriers make connecting the lower levels to the cloud much more difficult, often requiring multiple jump hosts, VPNs, or sometimes a combination of both. Therefore, it is made practically impossible to connect there, and usually OT engineers prefer a physical connection on the the factory floor itself.
Challenge 2: Data loss because of aggregation
Each layer of the automation pyramid can only communicate with its adjacent layers via pre-programmed point-to-point connections. This has advantages, but also disadvantages: As data moves up from the PLC level in traditional systems, it undergoes aggregation. This aggregation causes a loss of detailed information that may be crucial for advanced analysis.
Example: the vibration / acceleration of a cutting tool is measured with 20kHz (20 thousand times per second) and the PLC takes this data, and calculates the average, an FFT and some other parameters (there is an entire science directed at vibration analysis, so I don't want to go into the details here). The system above the PLC might now only receive these aggregated parameters, and will show the human operator only the average values (if at all), or mostly just a "vibration OK" message. The MES system then only takes this "vibration OK" message and pushes it into the maintenance system. Now when you try from the cloud to get the raw data for predictive maintenance, you will only receive very aggregated data. Connecting to the shop floor to get the data directly from the PLC is also difficult (see challenge 1).
Challenge 3: Cultural differences between IT and OT
Both teams have different knowledge and origins. This causes massive organizational challenges. IT doesn't understand the requirements of real-time deterministic programming and OT doesn't know basic IT best-practices such as version control (yup, the industry best-practice to version PLC programs is by using the data and a suffix like "vFinal_now_really_v2"). This inevitably causes conflicts within the organization. See also the differences between IT and OT further above.
Reading this article from an IT perspective, if might be tempting to discard OT as old-fashioned, and enforce IT best-practices across the entire automation pyramid. For example, using normal computers programmed with "normal programming languages". The problem with this approach is that IT has no easy solution for deterministic and real-time systems, so it would require very rare experts in embedded programming to do that.
So we are stuck in the middle where we need both IT and OT to cooperate in spite of their differences.
Summary
The challenges outlined in Chapter 2 illustrate a complex landscape where traditional automation systems, characterized by their rigid, localized, and non-integrated nature, face significant hurdles when interfacing with advanced cloud-based IT practices. These issues not only encompass technical and data aggregation obstacles but also underline profound cultural differences between IT and OT environments.
In the next chapter, we will discuss the UMH, and how these integration challenges can be addressed.
How the United Manufacturing Hub is solving these challenges
The UMH was specifically designed to address these challenges and is available as an open-source project on GitHub. The UMH was developed by the original system integrator before UMH, who were deeply frustrated by the solutions offered by established vendors: tools that cost multiple millions of Euro were really bad. There had to be a better way...
First, we will look at the origins of the UMH, how it evolved over time, and the architectural decisions made along the way. Then, we take a look at how the current architecture is solving the integration challenges outlined in chapter 2.
UMH started with the MING stack
The UMH developers found inspiration in an open-source solution, that already outperformed traditional tools, called the "MING stack". MING stands for Mosquitto (MQTT broker), InfluxDB (database), Node-RED (data integration) and Grafana (data visualization). The MING stack was used as the basis for what would later become the UMH.
Initially, the UMH team ran a version of the MING stack via Docker Compose. The problem with this approach was that a lot of configuration remained to be done after each installation. Later, Docker Compose was replaced in favor of helm and K3s for this purpose. K3s is a minimal version of Kubernetes, which allows users together with Helm to preconfigure the tools, e.g. data model for Grafana and InfluxDB so that the user doesn't have to reconfigure this themselves. The other components of the MING stack were gradually replaced to better fulfill the particular needs of the manufacturing industry, as discussed below:
A: Mosquitto --> HiveMQ + Redpanda
Focusing on the data acquisition part, MQTT is the ideal protocol to connect many devices over unreliable networks. Initially designed by IBM, it's a very simple protocol that's recognized by many industrial machines. However, MQTT is not designed for fault-tolerant and scalable stream processing as discussed in this article by the UMH. Therefore, the data processing engine was reinforced with Redpanda (Kafka). Redpanda easily integrates with IT systems, is excellent at processing and storing large amounts of data, but is bad at handling devices that are unreliable (go on and off). This is where MQTT comes in. The combination of MQTT and Redpanda allows for an architecture that can process large amounts of data arriving from unreliable sources and storing it reliably.
As detailed in this UMH blog, the Mosquitto broker was eventually replaced with VerneMQ and later with the HiveMQ broker. The simple reason is that HiveMQ was in UMH’s opinion the only reputable company to offer an enterprise contract. This is an important condition that manufacturers generally require to feel confident.
B: InfluxDB --> Timescale
Concerning the database for long-term storage, InfluxDB was eventually replaced by TimescaleDB as detailed in this article. The decision boils down to a need for having a proper relational database. TimescaleDB is built on Postgres and therefore fulfills this condition. The added benefit is Postgres being a very mature technology instead of a shiny new tool.
C: Node-RED --> Node-RED + benthos
Focusing on data connectivity, Node-RED was chosen as the open-source tool to process data from many sources and convert it into MQTT (so that the data can be processed by the services connected to the MQTT broker).
Node-RED has a graphical user interface, where input nodes are connected to process nodes and output nodes via visual arrows to create data flows. While IT professionals prefer code, this approach sits really well with the OT crowd. Node-RED has a big community, offers lots of out-of-the-box connectors, and suffices for "good enough" solutions. The downside is that Node-RED is essentially one large Node-JS program that crashes if something somewhere goes wrong.
This is why the UMH uses Benthos in addition to Node-RED. Benthos, preferred by IT for its stability under high loads, uses YAML files to configure inputs and outputs. The UMH uses a custom fork of Benthos called "Benthos UMH" that includes OT specific connectors such as Siemens S7, Beckhoff ADS or OPC UA, which is a common protocol encountered in manufacturing. By having both Node-RED and Benthos, the UMH offers the best of both worlds to both IT and OT.
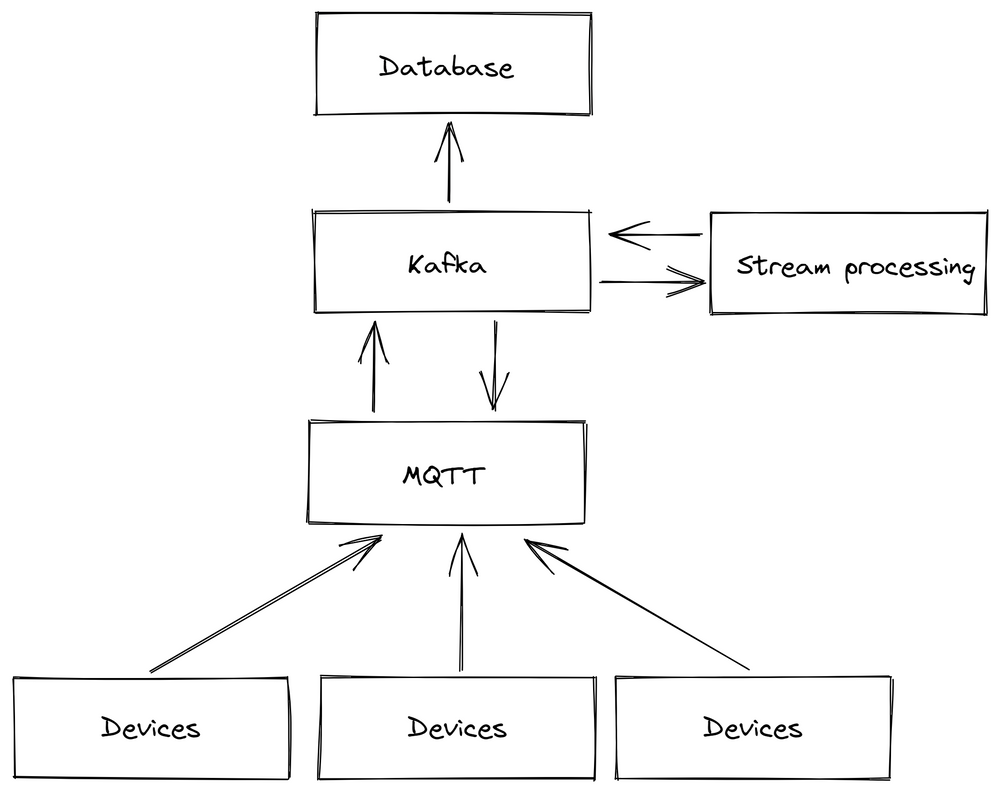
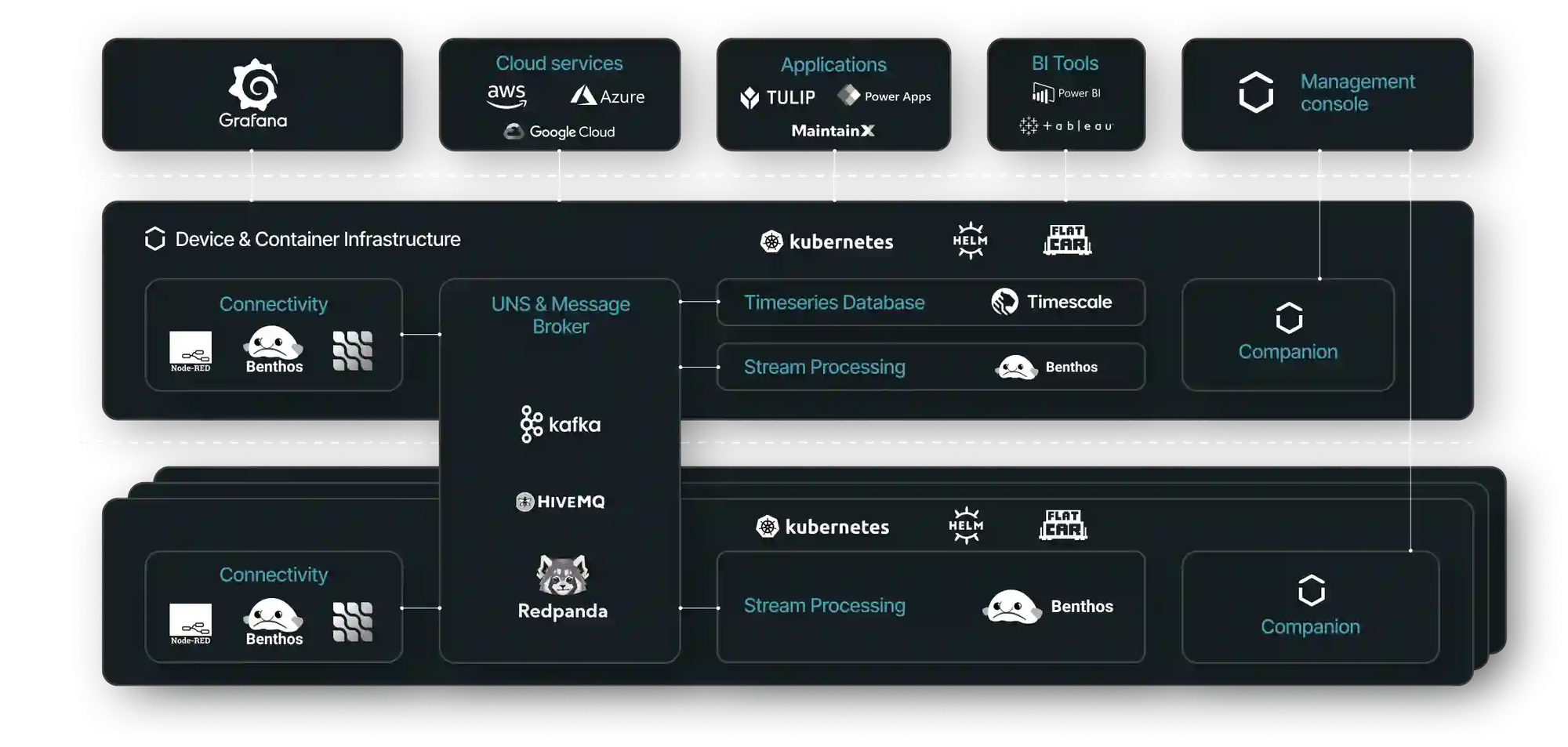
Current UMH architecture
Now going back to the original challenges mentioned in chapter 2. The UMH provides a solution for all three of them:
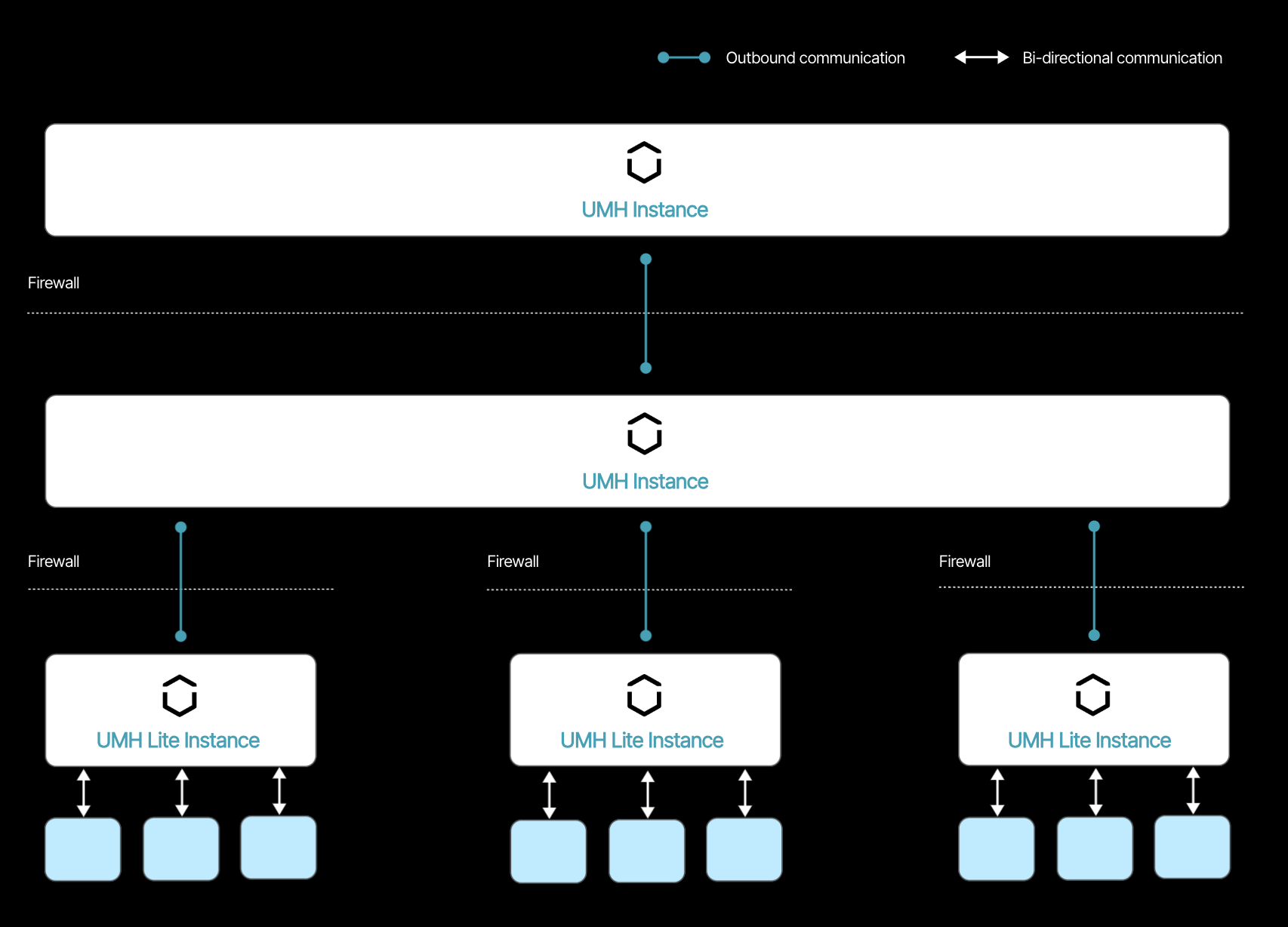
Challenge 1: Handling Security
The image below shows that the UMH stack is designed as a distributed system. At the bottom, individual UMH Lite instances collect data directly from the machines. These instances then communicate this data upward with only a single outgoing connection to the central UMH instance of the plant. This data is "saved" intermittently in the message broker which prevents in case the connection between a UMH Lite instance and the central UMH instance goes down. When one UMH Lite instance goes down, the others keep working. Optionally, another central UMH instance in the cloud could collect data from the individual central UMH instances at each plant. This approach ensures that only one connection from the shop floor should be white-listed in the firewall.
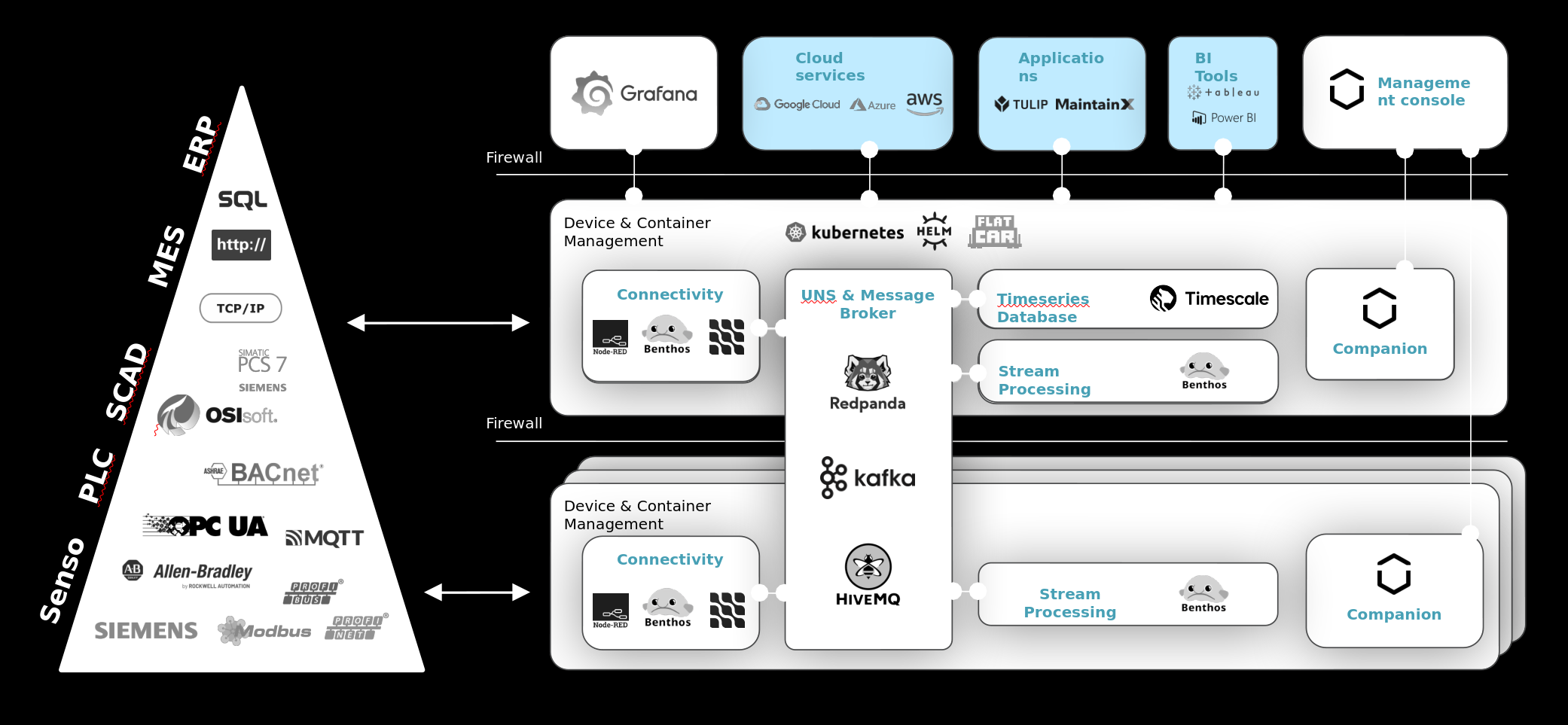
Challenge 2: Data-loss because of Aggregation
This architecture not only solves the security aspect, but also the aggregation aspect: on each layer of the automation pyramid is at least one UMH instance, that extracts the data and pushes it into the "Unified Namespace". With this, raw data can be extracted and passed to higher systems without endangering the stability of the existing automation solutions.
The image below shows that the UMH does not replace the automation pyramid. Rather, they both coexist where the automation pyramid is responsible for control and the UMH for analytics. The UMH is designed to easily integrate with both OT and IT systems at the plant and extract their data.
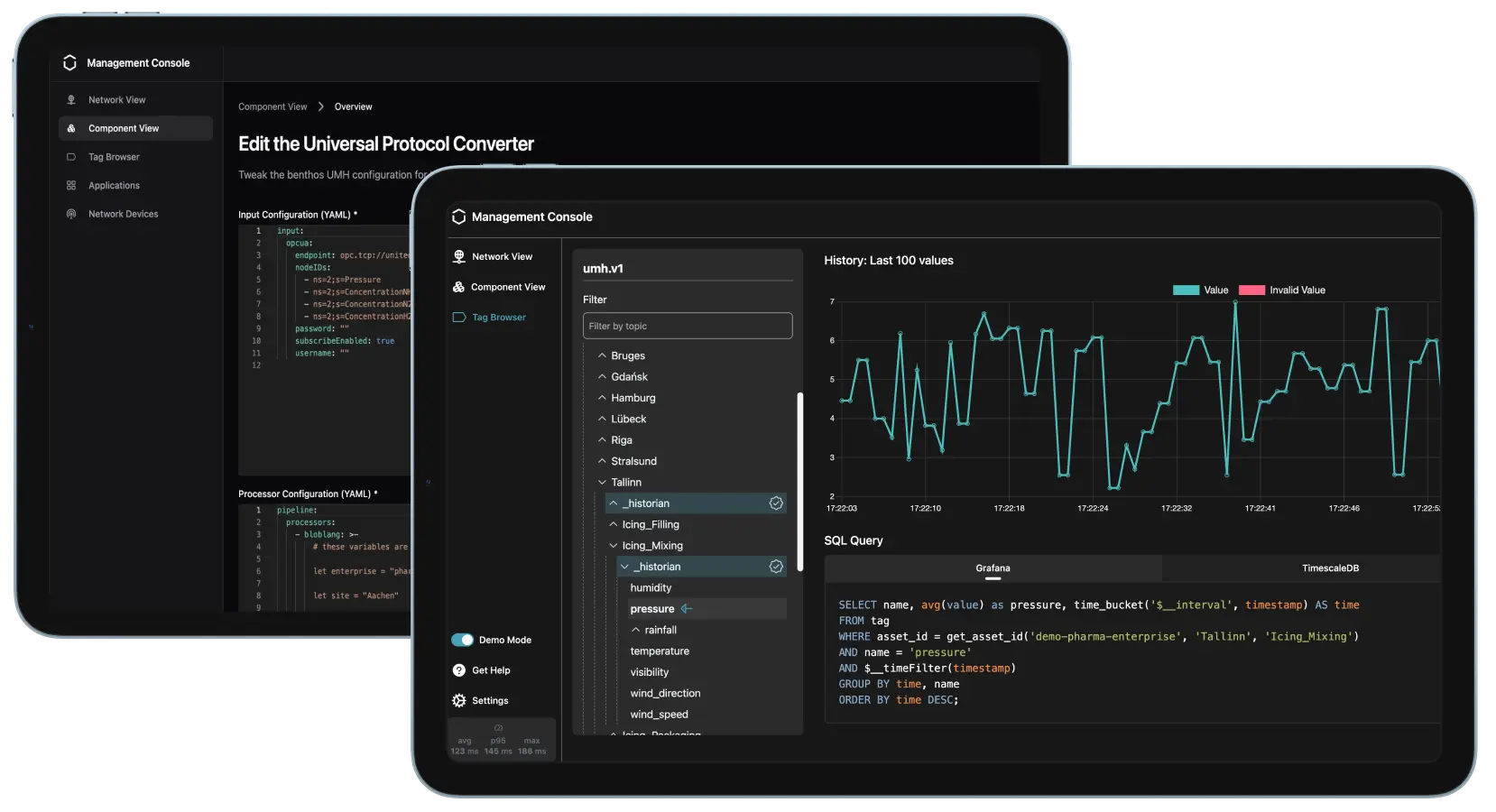
Challenge 3: Cultural differences between IT and OT
As mentioned above, the UMH is an IT-solution that finds its origins in OT. This means that its architecture is deeply rooted in IT-best practices but is very aware of the intricacies of OT. The objective is to have a system that can be used by both IT and OT personnel, ideally having both teams cooperate.
A concrete example of this approach is the UMH's Management Console. This is an add-on installed alongside the UMH that communicates important metrics to a web server so that they can be viewed using any web browser. Additionally, the Management Console handles updates, configuration and all other steps required in the overall lifecycle.
This gives both IT and OT have a good overview of the entire UMH architecture. The Management Console can either be configured in YAML (for IT) or by clicking around in its UI (preferred by OT). Metrics and logs can be analyzed with Prometheus (for IT) or using the "tag browser" in the UI (for OT). The tag browser gives an overview of real-time data that's being processed by the UMH.
Conclusion
I know, connecting a USB stick to the cloud might seem a bit exaggerated. Yet, in manufacturing, we are not far from this reality. Ultimately, manufacturing systems represent a complex distributed network, yet easy-to-use IT solutions are scarce, leading many to continue relying on OT.
The approach showed here is about modernizing manufacturing through the integration of cloud-native technologies. By leveraging advanced tools like Kubernetes, Grafana, and TimescaleDB, along with robust systems such as Kafka and MQTT, the UMH has proven that bridging the gap between traditional manufacturing operations and cutting-edge IT solutions is not only possible but essential.
Feel free to try out the UMH yourself, if you want to learn more!


