

The United Manufacturing Hub is an Open-Source toolkit to build your own reliable and secure Industrial IoT platform. We've been working since 2017 in the field of data processing in Industrial IoT / manufacturing. We began with a naïve "send all data to the cloud" approach and through various industry projects evolved into a Helm Chart for Kubernetes bringing the worlds IT into the hands of engineers.
This article is focused on our experiences with the tools and technologies we encountered on the way, the reasons we landed up with the current architecture of the United Manufacturing Hub and where we are currently working on.
It is split into three phases and these phases are typically the ones that a lot of companies are going through (we will link to publicly available use-cases whenever possible):
- "Sending all data to the cloud"
- Federated MQTT stream processing / "Unified Namespace"
- MQTT with Kafka-based stream processing
1. "Sending all data to the cloud"
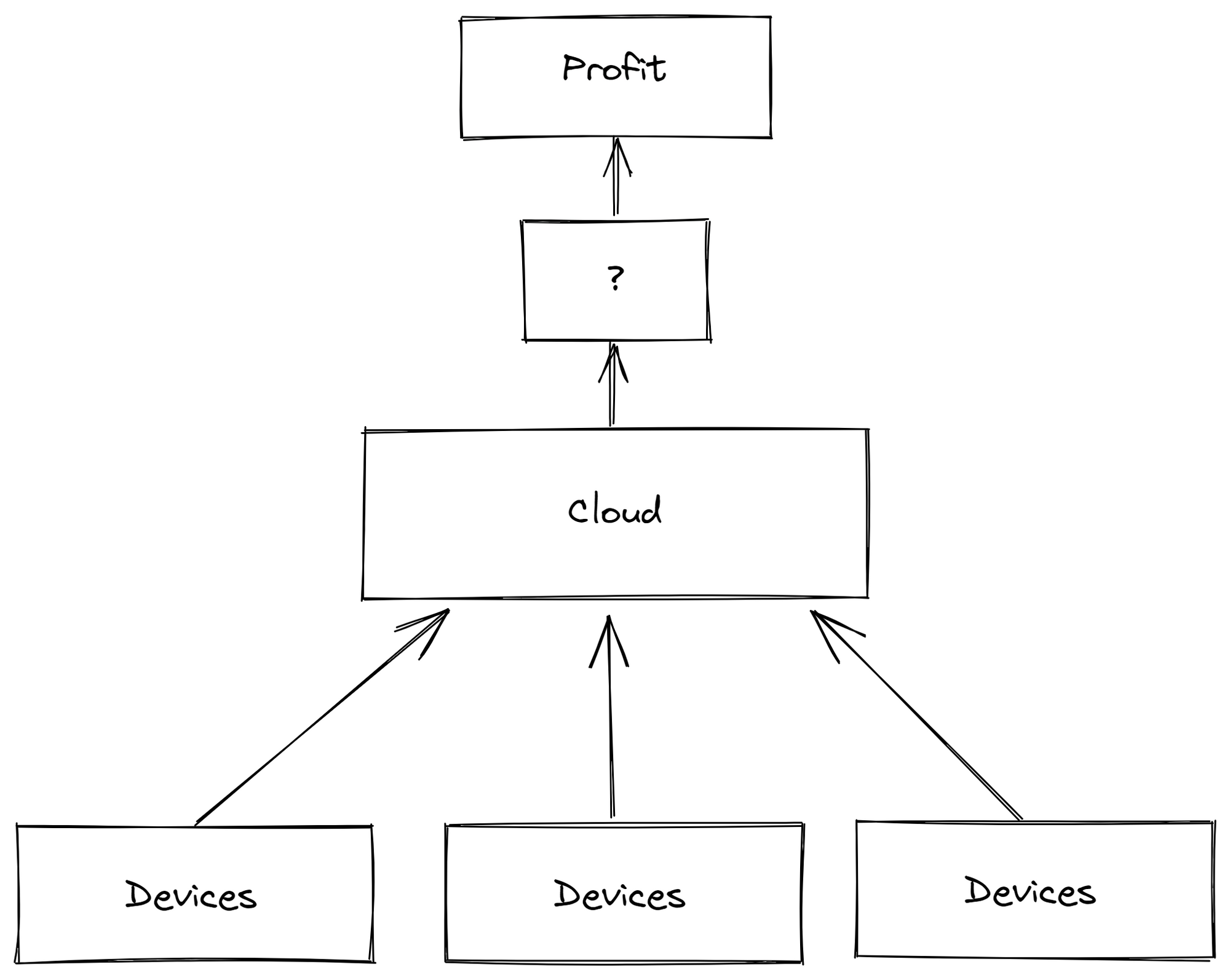
This approach is often the first approach that companies take on Industry 4.0 or the Industrial IoT. It comes from the field of IoT and involves sending all data points directly into the cloud for later data analysis.
Typical tools here are:
- Managed message broker like Azure IoT Hub or AWS IoT Core or self-hosted MQTT broker like VerneMQ , HiveMQ, mosquitto, etc. running on Azure or AWS
- Cloud-based databases and stream processing tools, like Amazon DynamoDB, AWS Lambda or Azure Functions
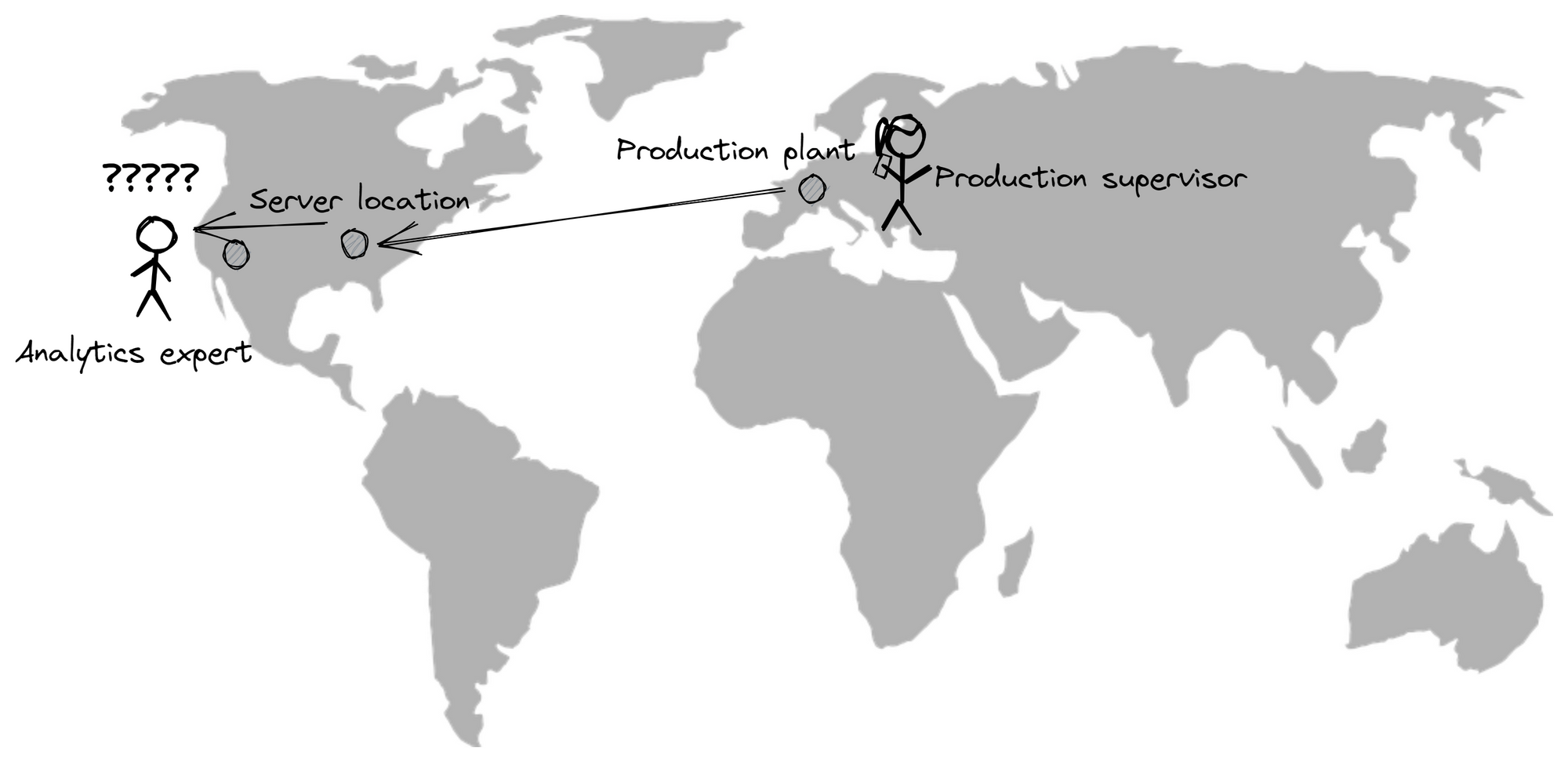
One of our biggest challenges was that this architecture made certain use cases impossible, such as machine learning directly at the machine, because internet connections are often not suitable (latency and upstream/downstream limitations) and it was therefore not possible to use a cloud broker. Some data just needs to be handled on the edge.
Furthermore, this type of architecture strongly encourages coupling programs and machines with each other, which makes maintenance and the integration of new use-cases much more difficult: It is hard to reuse the PLC data, if the PLC directly writes into a cloud database.
Additionally, multiple customers reported that their IT departments lacked transparency about where the data is coming from and struggled making sense of the (mostly raw) data in the cloud. Most machines and factories and very different from each other and the raw data mirrors exactly that.
There are solutions out there promising to make the contextualization across machines and factories "fully automated". Until now, we have not heard yet from any customer in discrete manufacturing that this actually works. And even if it works, there are still limitations regarding certain use-cases (see above).
Because of that feedback we, and other companies like BMW, decided to take a different approach and solve these challenges.
2. Federated MQTT stream processing / "Unified Namespace"
We called this approach federated MQTT stream processing. Other names for it are "Unified Namespace", "Message Bus" or "event-driven architecture".
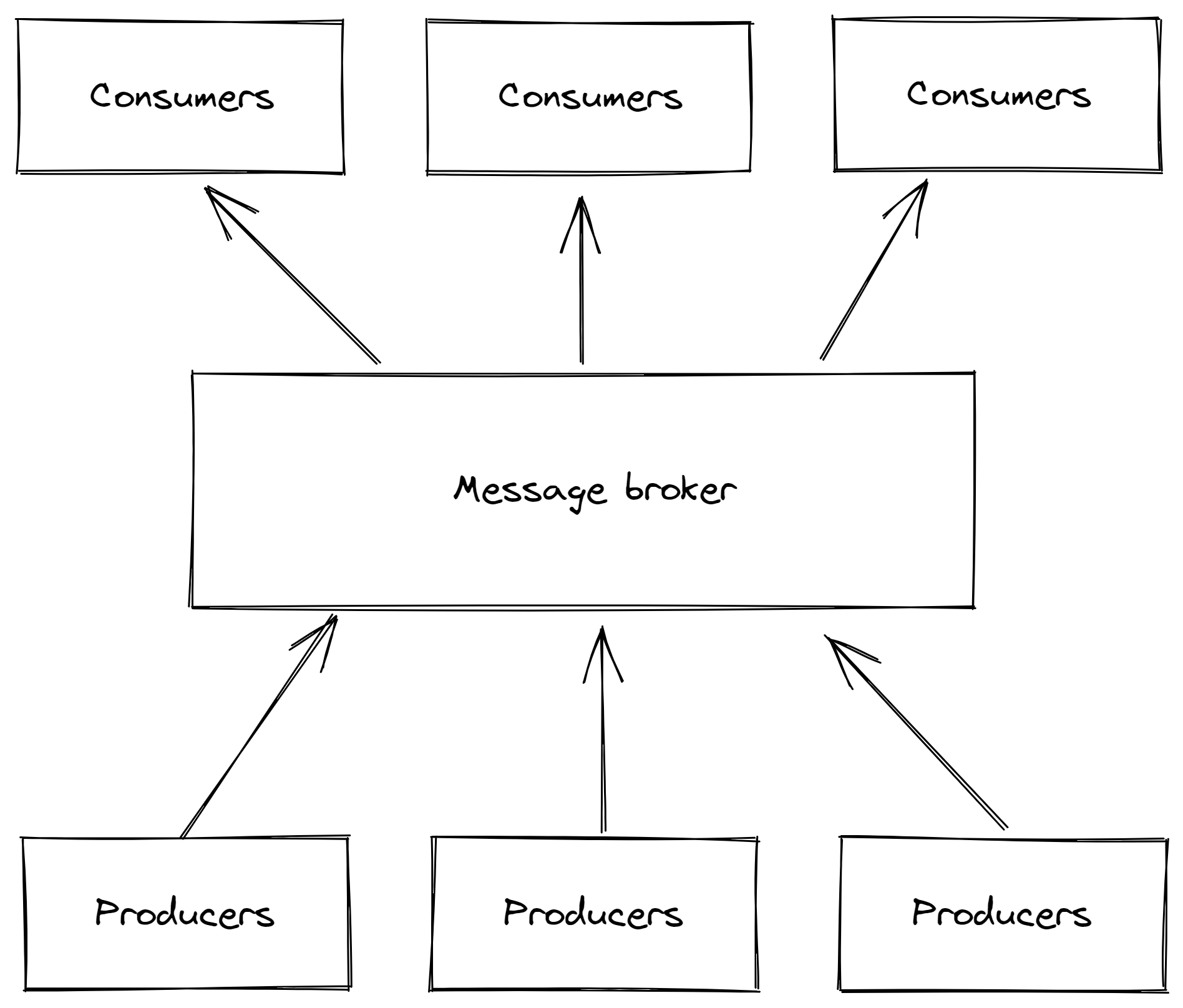
Here, the data is not sent directly from the producers to the consumers, but a so-called message broker is interposed. This adds another component and thus increases the likelihood of a system failure, but on the other hand (and this is a big plus) it makes it easier to integrate new machines, services, solutions or databases.
Additionally, instead of having one central message broker, we decided to go for one for each factory. This enables not only factories working independently from the cloud, but enables all use-cases we can think of in Manufacturing (like edge computing).
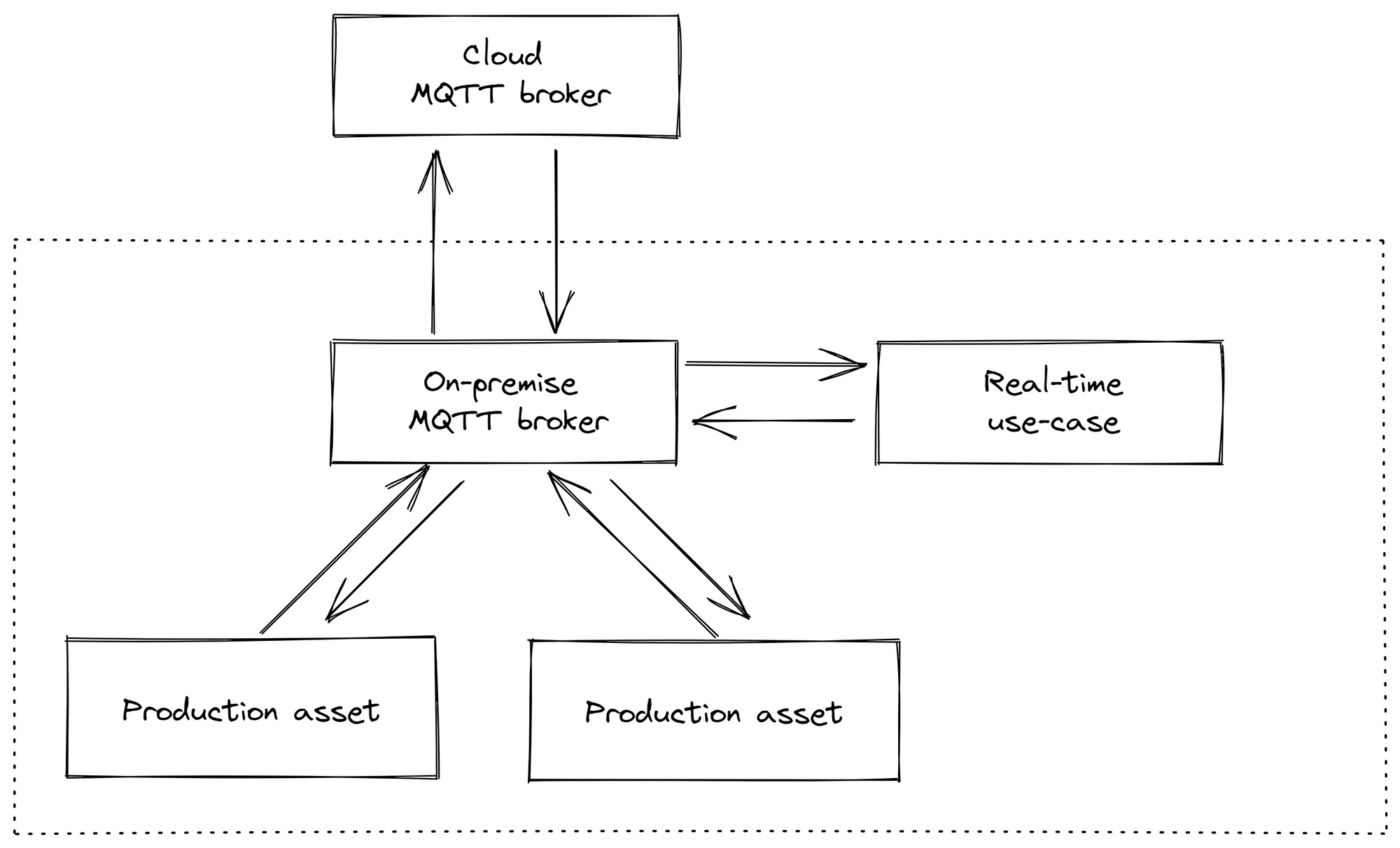
As message broker we chose because of the popularity and simplicity MQTT. MQTT is great to handle millions of devices at the same time while still being relatively simple (compared to protocols like OPC/UA)

We would then gather data from production machines, put it into an MQTT broker, contextualize it on the edge using multiple microservices and then send it to the cloud MQTT broker, where the data would automatically be stored in a database.
This architecture provides the following advantages:
- Independence from internet outages. The production is not disturbed and can can continue to operate.
- Data transparency. It is easy to see know which data is available.
- Decoupling. It is easy to integrate new use-cases as you can "just plug them into the MQTT broker"
We went with this approach for almost three years until we realized two road blockers when scaling this architecture:
A) MQTT is not designed for fault-tolerant and scalable stream processing
Stream processing is the part where you take data out of the broker, process it and push the results back to the broker.
Where above architecture struggles are the edge cases:
- hard device restarts (e.g., loosing power) causing a queue corruption
- Duplicated messages caused by problems in the network
- Messages not processed at all / lost caused by overloading certain microservices, microservice restarts
- A combination of all elements happening at the same time
Example
To explain the whole thing a little more clearly, here is an example:
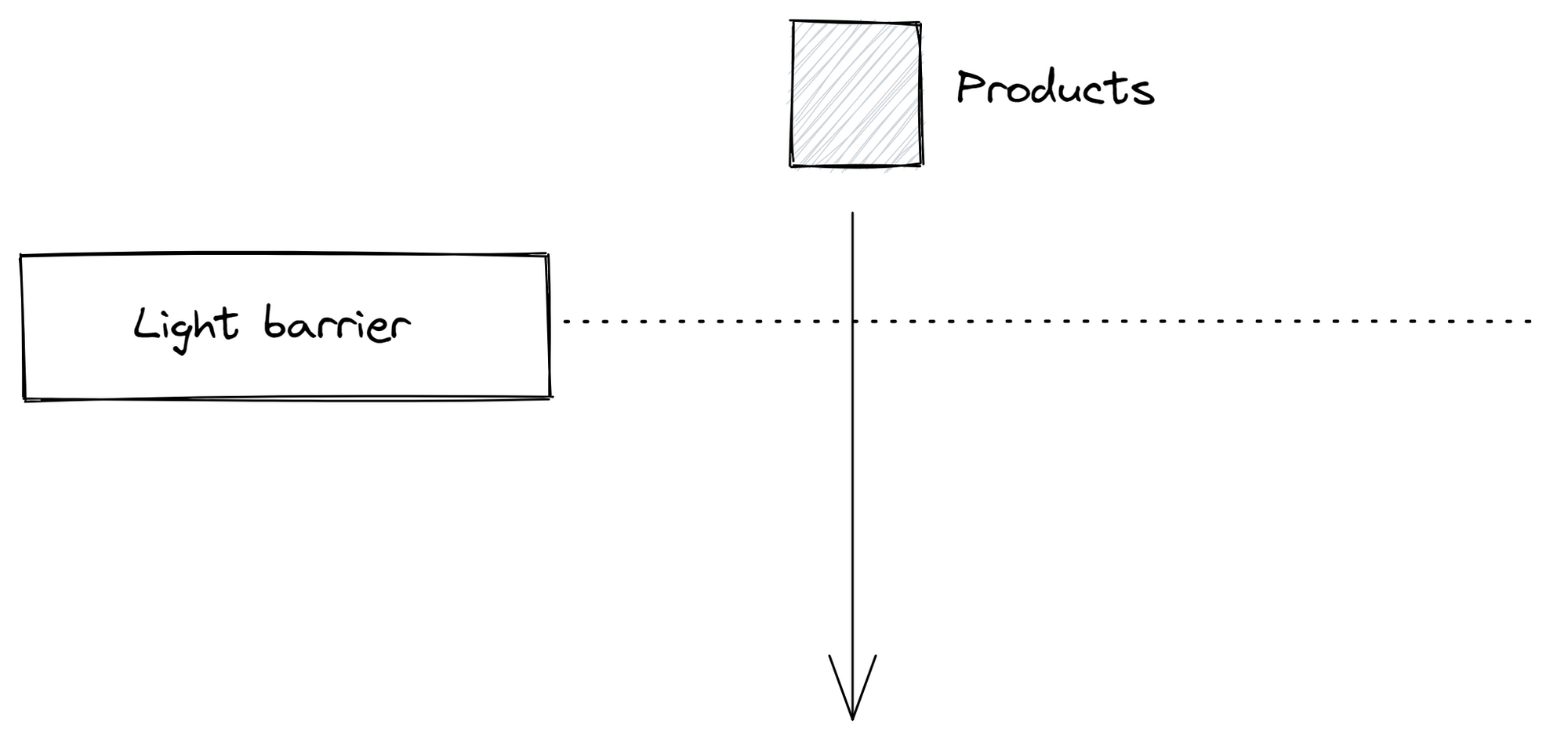
Imagine we want to determine the output quantity of a machine and the data comes in via a light barrier. The photoelectric sensor measures the distance and when the distance gets smaller, a product is passing by and a message "count" is sent to the MQTT broker. In this case the light barrier is microservice A.
There is now also a Microservice B that calculates the output quantity from these "count" messages, e.g. "produced pieces last hour".
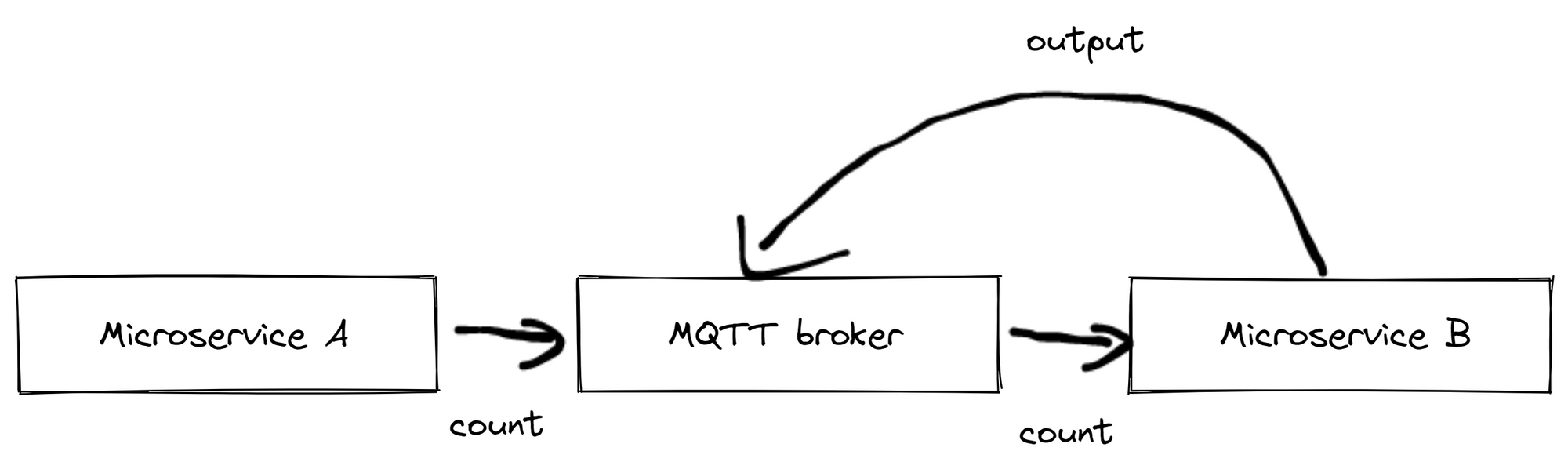
An implementation for microservice B usually looks like this:
- It is subscribed to the topic of the "count" messages.
- The current output quantity is stored in the program, if necessary it is retained in the MQTT broker.
- The "count" message is taken, the number of produced products is extracted and the current output quantity is increased.
- The current output quantity is now sent back to the MQTT broker.
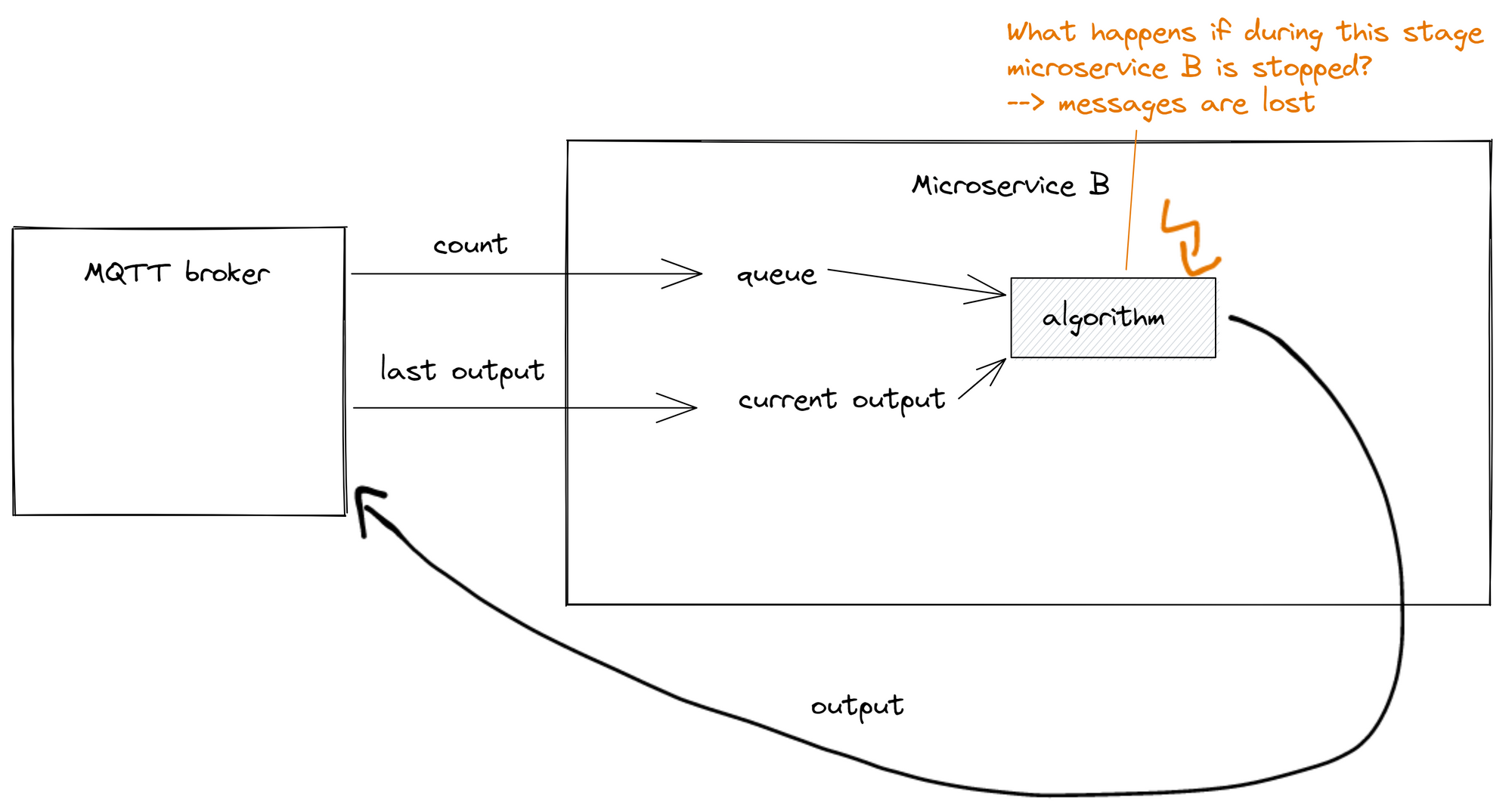
But what happens if there are some messages in front of B and B receives 10 messages at once and crashes (maybe because of another reason). If Microservice B is restarted, these 10 messages would be lost, because Microservice B has already received them.
These cases are very unlikely, but the probability is never zero. Once you connect hundreds of devices, the probability increases and you start noticing them.
And suddenly you spend most of your time trying to cover these edge cases in code with redundancy, more queues, and more lines of code. And the implementation of these edge cases is something that large technology companies like Netflix are still working on to get in properly working.
There are two options on how to work around with MQTT
One approach to mitigate the issues in above examples is using queues. We first pushed all incoming messages into a LevelDB database and wrote them to disk. Then each message is read again from the LevelDB database. Unfortunately, LevelDB has a history of database corruption bugs, especially during hard device restarts (which are way more common on the shop floor than in protected server farms). This resulted in data loss when doing frequent device restarts. You could also then switch to log-based queues (so databases writing everything into an append-only log), but then one would be reprogramming Apache Kafka (see also next chapter)
Another approach is to acknowledge MQTT messages only if these messages have already been processed successfully. Should a crash then occur, the MQTT broker (with a correct implementation) would send the message again.
There are three disadvantages here:
1. It is an unsupported workaround
First, this is a workaround as the MQTT standard clearly states that the messages should be acknowledged as soon as the message was received (see MQTT v3.1.1 standard):
Three qualities of service for message delivery:
[...]
"At least once", where messages are assured to arrive but duplicates can occur
2. It reduces the possible throughput
Second, it significantly reduces the possible throughput as the maximum amount of inflight MQTT messages is limited
3. Unstable implementations
Third, the broker and client implementation. Theoretically, this resending of messages should be possible when using QoS (Quality of Service) of MQTT. However, the MQTT standard does not provide a solution on how this should be implemented and so the implementations are left to the creators of each MQTT library and broker (see also paho.mqtt on Stackoverflow, paho.mqtt for golang has a undocumented version, which does not seem to work)
The last point also brings us to our next topic.
B) The Open-Source MQTT ecosystem is mostly focused on small use-cases
We have also found that parts of the Open-Source MQTT ecosystem (brokers and client libraries) are unreliable in larger constellations, and we have heard this from other vendors working in this area. We are not saying that all solutions are unreliable, just that it is sometimes difficult to see the limits of the individual systems.
Some examples:
- Large MQTT libraries like paho.mqtt do not reconnect after a disconnect or simply hang for unknown reasons. Typical workarounds include sending a message back and forth to the server, and if no message arrives within x minutes, restarting the MQTT client (this is no joke)
- MQTT bridges from various vendors losing data
- Client libraries not buffering messages during downtimes of the brokers or connection problems
- MQTT standard only partially implemented, especially in hardware devices
- Managed MQTT services from large cloud providers not being able to handle more than 10k messages / second
The list can be continued indefinitely. We tried to solve the problem by introducing workarounds and additional queues, which only made the system more complex and prone to errors and malfunctions.
Be aware from propriety black-box one-fits-it-all solutions praising how seamless MQTT works on their side. They might just use the same Open-Source libraries and brokers. But there are propriety MQTT brokers like HiveMQ out there with their own custom written brokers and client libraries, which might help mitigate some of the issues mentioned above.
C) Summary
MQTT is designed for the safe message delivery between devices and not for reliable stream processing. Additionally, parts of the Open-Source MQTT ecosystem (and all vendors that are building on top of it) are unreliable. We've worked with it for a couple of years, introduced more and more workarounds, but were still struggling with reliability.
A different approach was needed.
And an approach that is ideally already used in the industry and is considered best-practice.
3. MQTT with Kafka-based stream processing
We've took a look how large companies in insurance, automotive and banking are solving these challenges. One best-practice we've found is to use Apache Kafka.

Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Based on their own statements "more than 80% of all Fortune 100 companies trust, and use Kafka".
How Kafka works
The principle is similar to the one of an MQTT broker:
1. There are consumers and producers (both are also called clients) with a broker in the middle
2. Messages, or in Kafka terminology events, are published by a producer to a topic and can then be consumed by another microservice
The difference is that each event gets written into a log to disk first. This sounds like a small detail at the beginning, but because of it Kafka can guarantee you message ordering, zero message loss and efficient exactly-once processing even in the harshest environments.
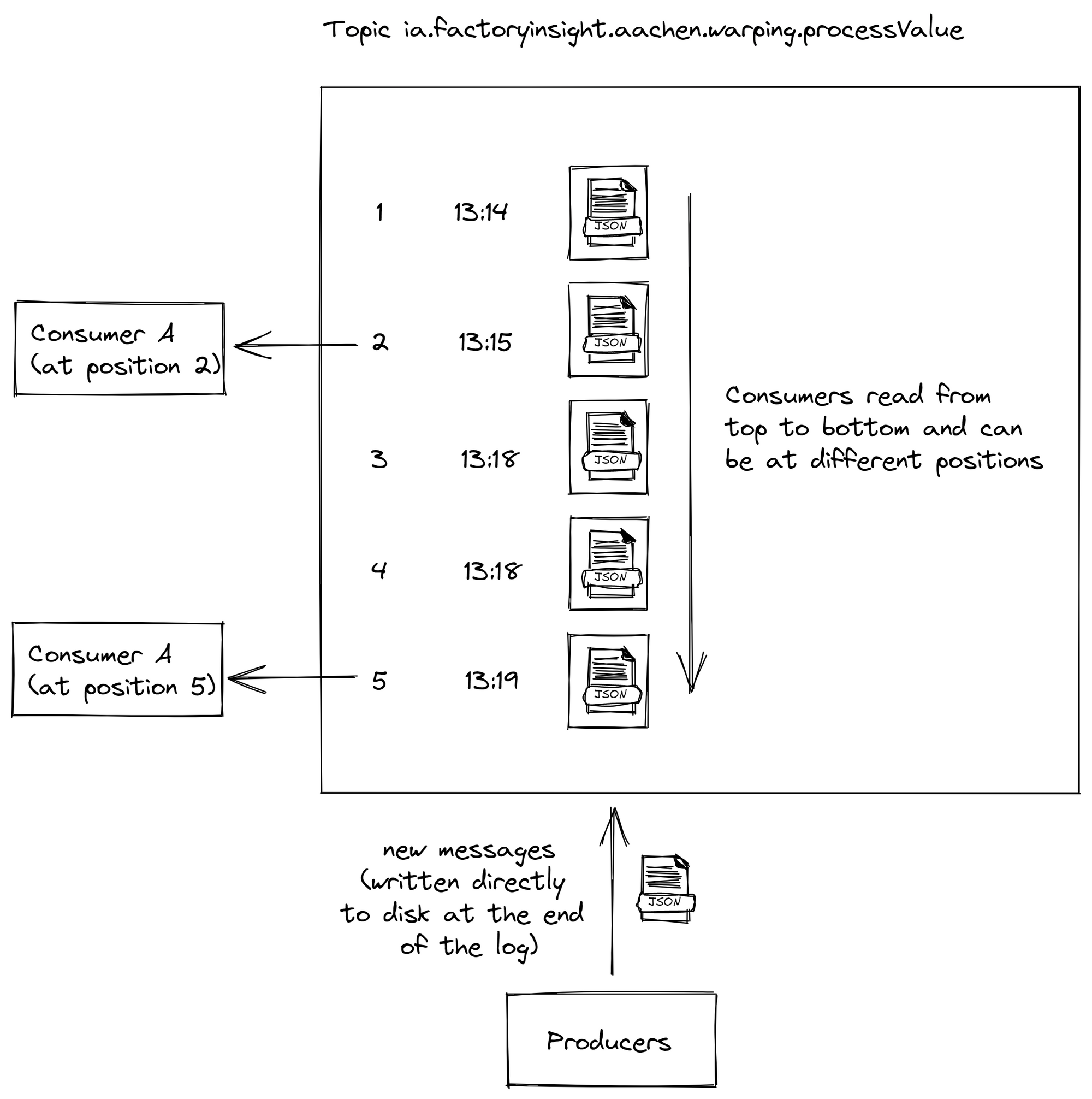
How we use Kafka in the United Manufacturing Hub
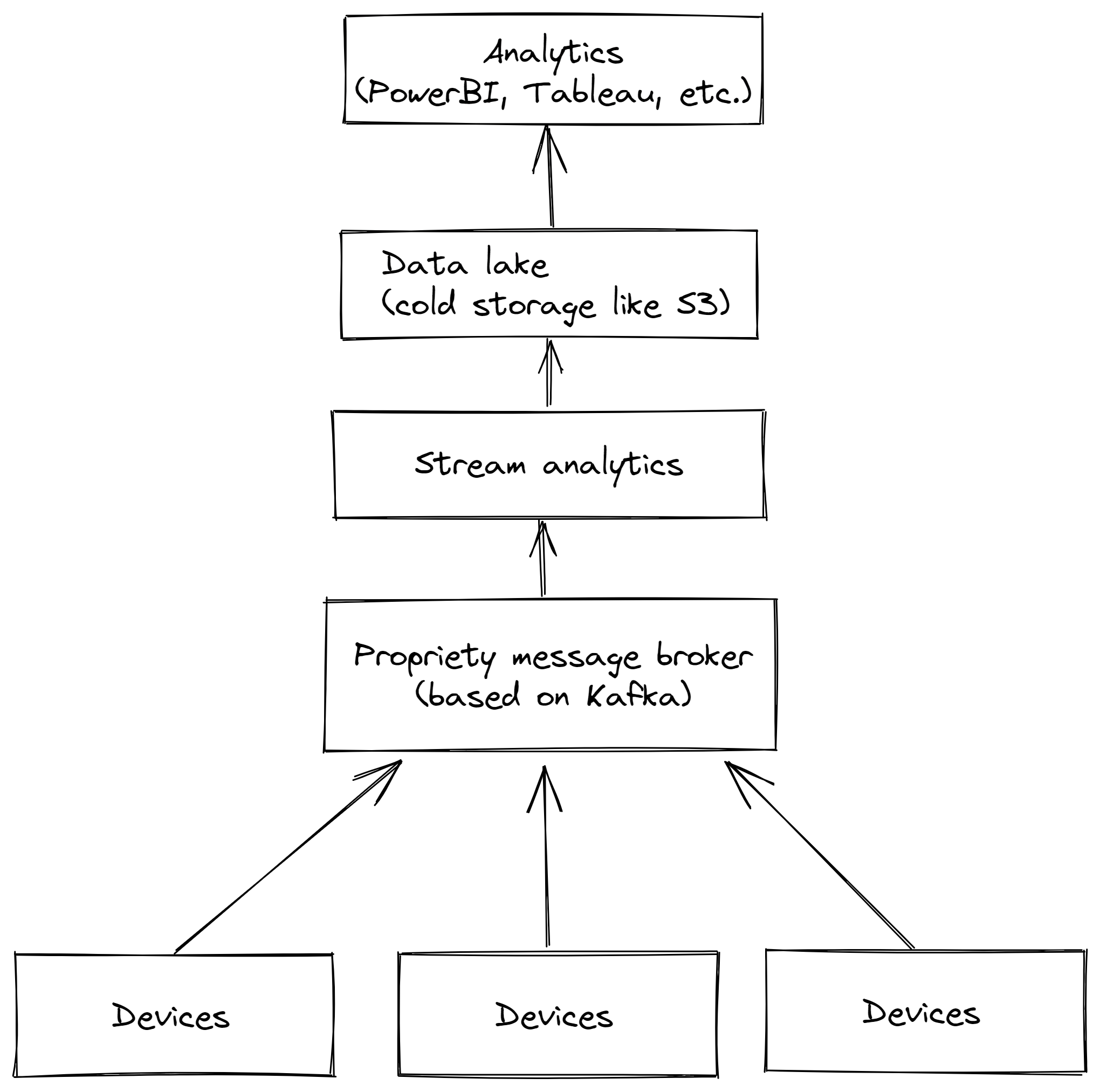
So what we did is we use an MQTT broker to gather data from various devices across the shopfloor and then we bridge it to Kafka to contextualize and process it. With this approach we are combining both the strengths of MQTT and Kafka.
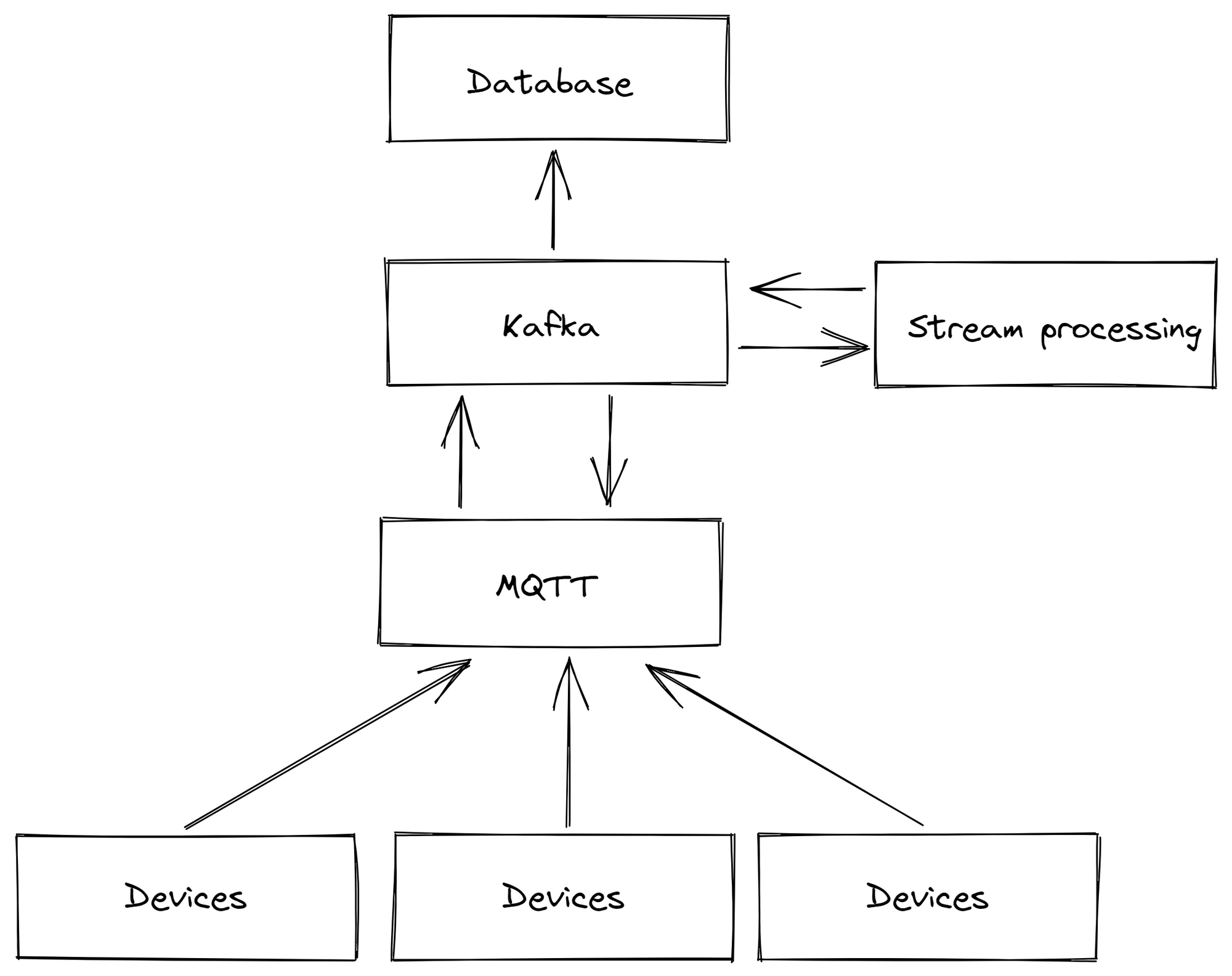
And so far it looks very good, even when hundreds of thousands of messages per second are sent through "unreliable" devices and networks. If a microservice fails, all messages are reliably cached by Kafka.
And we are not the only ones. Companies like aedifion entirely moved away from MQTT and switched fully to Kafka, other companies like BMW use Kafka as we in parallel to MQTT.
Kai Waehner from Confluent provided us with even more examples:
Apache Kafka and MQTT are a perfect combination for many IoT use cases.
The integrated deployment enables data streaming from the last mile of the OT world into real-time, near real-time and batch applications in the IT infrastructure.
A great example is Baader, a worldwide manufacturer of innovative machinery for the food processing industry.
Baader runs an IoT-based and data-driven food value chain on serverless Confluent Cloud. The single source of truth in real-time enables business-critical operations for tracking, calculations, alerts, etc. MQTT provides connectivity to machines and vehicles at the edge. Kafka Connect connectors integrate MQTT and other IT systems such as Elasticsearch, MongoDB, and AWS S3. ksqlDB processes the data in motion continuously.
More information about the Baader case can be found here
Additional features from Kafka
In addition, we have message compression enabled by default and automatically append tracing information (what message was created where and what were the error messages) via Apache Kafka headers. If a message fails to be processed it gets stored in a different "putback-error" queue, which helps in troubleshooting malformed messages and keeps the main processing clear. Furthermore, it promotes transparency as one can now see where which datapoints is coming from.
We are also able to treat messages differently depending on their importance.
All "business relevant" information like new orders or produced parts should go through a "high integrity" pipeline. Here we guarantee at-least-once delivery. Process values such as temperatures pass through the "high throughput" pipeline, where we deactivated the guarantee for performance reasons.
More information on our implementation can be found in the documentation.
You might ask one question: why are we even using MQTT and why did we not switch entirely to Kafka?
Two reasons:
- It is simple and therefore it is easy to gather data on the shopfloor. If we leave it out we would miss on a huge opportunity to easily get data from the automation world.
- Node-RED right now only work stable with MQTT and not Kafka. Leaving it out would mean abandoning Node-RED and right now we have not found a user-friendly alternative for it yet
Outlook
Right now we are finishing up the transition by transforming the "core infrastructure" (e.g., microservices like sensorconnect fetching data from ifm IO-link masters) to directly use Kafka instead of MQTT. Additionally, we are moving as many standard elements out of the MQTT based Node-RED into more reliable microservices based on Kafka (e.g., PLC4X for PLC connection, counter microservices or machine state microservices)
Feedback? Feel free to write us!
We thank Marc Jäckle (MaibornWolff) and Kai Waehner (Confluent) for their valuable feedback in creating this article.


