Manufacturing “AI” is, frankly, a dumpster fire. The flames look impressive in every conference demo, but try standing next to them for an entire shift and you will feel the heat.
I pay $200 a month for ChatGPT‑Pro, use Cursor in MAX mode and talk about AI every single day - often enough that friends and colleagues have begged me to change the topic. So I am anything but anti‑AI; I am anti‑bad‑AI.
During the past year I have looked at nearly every “industrial agent” on the market. The pattern is always the same: someone pipes raw sensor tags into a language model and proudly asks, “Hey AI, what’s the temperature of Machine 5?” The bot replies, everyone claps, and the demo ends.
On a real plant floor that answer was already on the Human-Machine-Interface (HMI), and the operator never had time to ask in the first place. A rare counter-example is Tulip’s AI Composer. It turns PDFs—or even handwritten SOPs—into a working app by generating code first. Tools like this are still the exception, not the rule.
In the following I will put out three fires:
- First, we will see why chatbots are the wrong tool for frontline work.
- Next, we will look at the brittle architecture that makes live AI pipelines drift and drain budgets.
- Finally, we will show how even a single hallucinated reading can destroy trust and stall digital transformation.
After each fire I will point to the same extinguisher: let the AI generate code once, freeze it, test it, and run that deterministic pipeline forever.
In the end, I will show you how you can do it with UMH.
So let us start with the first blaze—chatbots on the shop floor.
Chapter A - Operators need dashboards, not chatbots
Picture the packaging line at full speed: motors humming at 90 dB, operators in gloves, ear‑defenders, and safety glasses. When someone wants to know the temperature of Machine 5, they glance at the HMI that refreshes every 200 milliseconds. They do not open a chat window and start typing a question.
Real‑time production needs data that is already correct and instantly visible—not a back‑and‑forth with a language model. Three things make the chatbot idea break down the moment you leave the demo room:
First, the information is right there.
Shipping the value to a cloud model and waiting for an answer adds network latency and one more failure point. If that link drops, the operator loses the number they could have read on the local screen.
Second, conversation does not scale.
A video demo usually shows the model fetching a single tag. In real life a cell streams thousands every second. Imagine typing “Pressure on filler 3?” … “Capper 2?” all shift long. The line would outrun the chat loop and the operator’s patience.
Third, meaningful questions are composite, not single.
A useful query sounds like “Are any fillers drifting out of spec right now?” That requires correlating hundreds of tags at once. A dashboard or an SQL query handles that in one shot; a chatbot would answer tag‑by‑tag until the shift is over.
Where a Chatbot Is Helpful
Put the bot in the back office, not on the line. A quality engineer at a desk can ask the model to write the SQL, run the query, and inspect the rows. SQL does not hallucinate; if the model names the wrong column the database throws an error, you paste that error back into the chat, and the loop tightens. The LLM becomes an accelerant, not an unreliable calculator.
That “generate → run → fix” loop is exactly the pattern we will return to in Chapter C, where trust and validation take centre stage.
Chapter B - Live Agents Drift; Frozen Code Doesn’t.
A language model can write a pipeline in seconds; the trouble starts when you keep the model inside that pipeline.
Most vendor demos follow an identical recipe. First they pour the entire Unified Namespace into an LLM. Next they hand the model a toolkit—functions like readTag(), getHistory(), createWorkOrder(). Then they ask a broad question such as “Is my line running okay?” and invite the audience to watch the agent call a tool, read the answer, pick another tool, and loop. On three conveyors this feels like magic: “Dump in raw tags and the AI adds perfect context!” On a real plant it collapses under its own weight.
Issue 1: Context burn
The agent must repeat the whole story on every pass: the tools it can use, the partial results so far, the next instruction. The prompt grows, latency stretches, and the token bill climbs from cents per datapoint to dollars per minute once you have a few hundred machines.
Issue 2: No snapshot → drift you can’t debug
Some will say “the prompt is the new code.” Maybe - but they don't mean this setting here.
People type questions differently, models receive silent updates, and the agent replans from scratch each time. Yesterday you logged “18 °C”, today you get “eighteen”, tomorrow the model replies “Machine 5 not found.” With no file to git diff and no commit to roll back, an FDA 21 CFR 11 auditor - or even your own team - cannot replay what happened. Debugging turns into archaeology.
English may well grow into a programming language, but a plant still needs a stable intermediate artefact - YAML, SQL, a script - something you can freeze, test, and sign. Let the AI generate that once, then run the deterministic pipeline and keep the guessing out of production..
Could live agents work one day? Possibly - teams are experimenting with evaluator loops, RAG, and other guardrails. Until those methods prove audit-grade, freezing the pipeline remains the safer choice.
Cost and drift are bad enough. The next fire—data quality and trust—burns even hotter, and that is Fire C.
Chapter C - Trust Comes from Tests, Not Promises
A pipeline you can test will always beat a chatbot you simply have to believe. Yes, you still let the model write the first draft, but you validate that draft once and then rely on code, not on fresh guesses.
Picture the night shift on a packaging line. An LLM announces “97 °C” on a filler that is obviously cold, then opens a maintenance ticket. The crew stops the line, hunts for a phantom heat source, and loses two hours of throughput. By breakfast the bot has a nickname—“Clippy”—and no one wants to hear from it again. One wrong answer can erase months of goodwill toward “digital transformation.”
One wrong answer can erase months of goodwill toward “digital transformation.”
Hallucinations are a feature of probabilistic models; you cannot abolish them. What you can control is where the hallucinations are allowed to happen. The safe place is design‑time, not production‑time.
The generate → freeze → iterate loop
Think of the LLM as a junior developer who works only in the staging lab. You give it access to the OPC UA server and the machine vendor’s handbook. The model crawls the nodes, matches signal names, and spits out a first draft of UMH YAML plus a Grafana dashboard. It also writes a small test suite — simple GraphQL checks that prove the data look sane.
You run the tests. If they pass, you commit the YAML and the dashboard to Git: that is your save‑point. Production now executes this deterministic pipeline, free of live AI calls.
Next month a new filler arrives. You spin up a feature branch, open a fresh chat, and let the model extend the YAML. The same test suite—plus any new checks the model proposes—runs again. Green tests? Merge and deploy. Red tests? Paste the failure back into the chat and let the model revise its own patch. Code → test → code—the rhythm that drives tools like Cursor. The AI supplies speed; the human supplies judgement. That pairing keeps the model powerful and contained.
To make this loop work you need exactly one clean interface - Model Context Protocol (MCP), CLI, plain HTTP, it doesn’t matter - as long as it lets the model execute the pipeline and read the test results. Most vendor stacks skip that detail, leave the agent running live, and inherit the drift and cost described in Chapter B. Build the interface once and you keep all the creativity of AI plus the certainty of repeatable software.
You don’t have to take my word for it. Armin Ronacher — creator of Flask and now VP Platform at Sentry — lays out the same “generate code, test it, freeze it” philosophy in “Tools: Code Is All You Need” (3 July 2025). Simon Willison — co‑creator of Django and an independent open‑source engineer — demonstrates the identical loop in “Mandelbrot in x86 Assembly by Claude” (2 July 2025), where he lets an LLM iteratively write and debug assembly until every test passes . Both authors reach the same conclusion: use the model to write deterministic artefacts, keep those artefacts in Git, and run production without the model on the critical path.
Conclusion
We have now walked through all three fires:
- Chatbots answer trivia but add no real value to a running line.
- Live MCP loops look clever in a demo, yet they drift, grow expensive, and leave auditors with nothing to replay.
- And one hallucinated number is all it takes to turn months of change‑management into a late‑night meme on the noticeboard.
The cure is simple and repeatable: let the model act as a junior developer at design time, then run the frozen code in production. When the AI has to change something, bring it back to the staging lab, regenerate the patch, run the tests, and only then redeploy. That way you combine the speed of AI with the reliability of ordinary software.
Imagine bringing a brand‑new line online in two days instead of two months, and never again paying someone to copy‑paste tags from one window to another. If that sounds better than tending a flaming dumpster, try out umh‑core together with a tool like Cursor. It will be able to automatically connect your production assets, model the data, test it and iterate. Further below some screenshots.
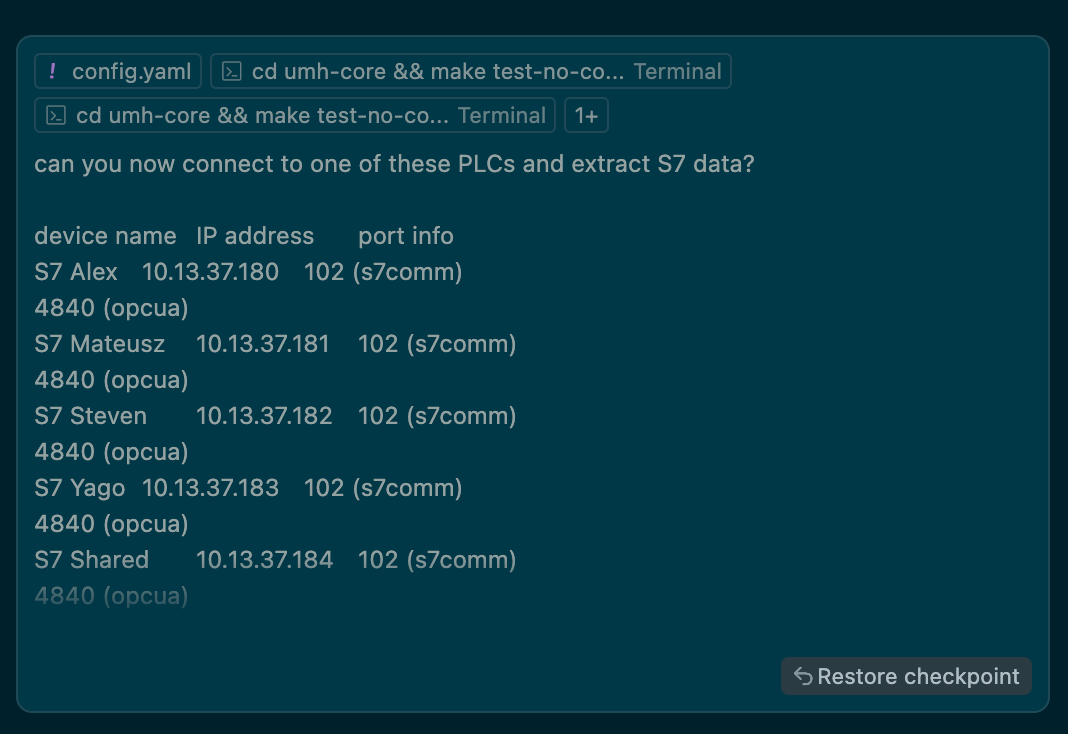
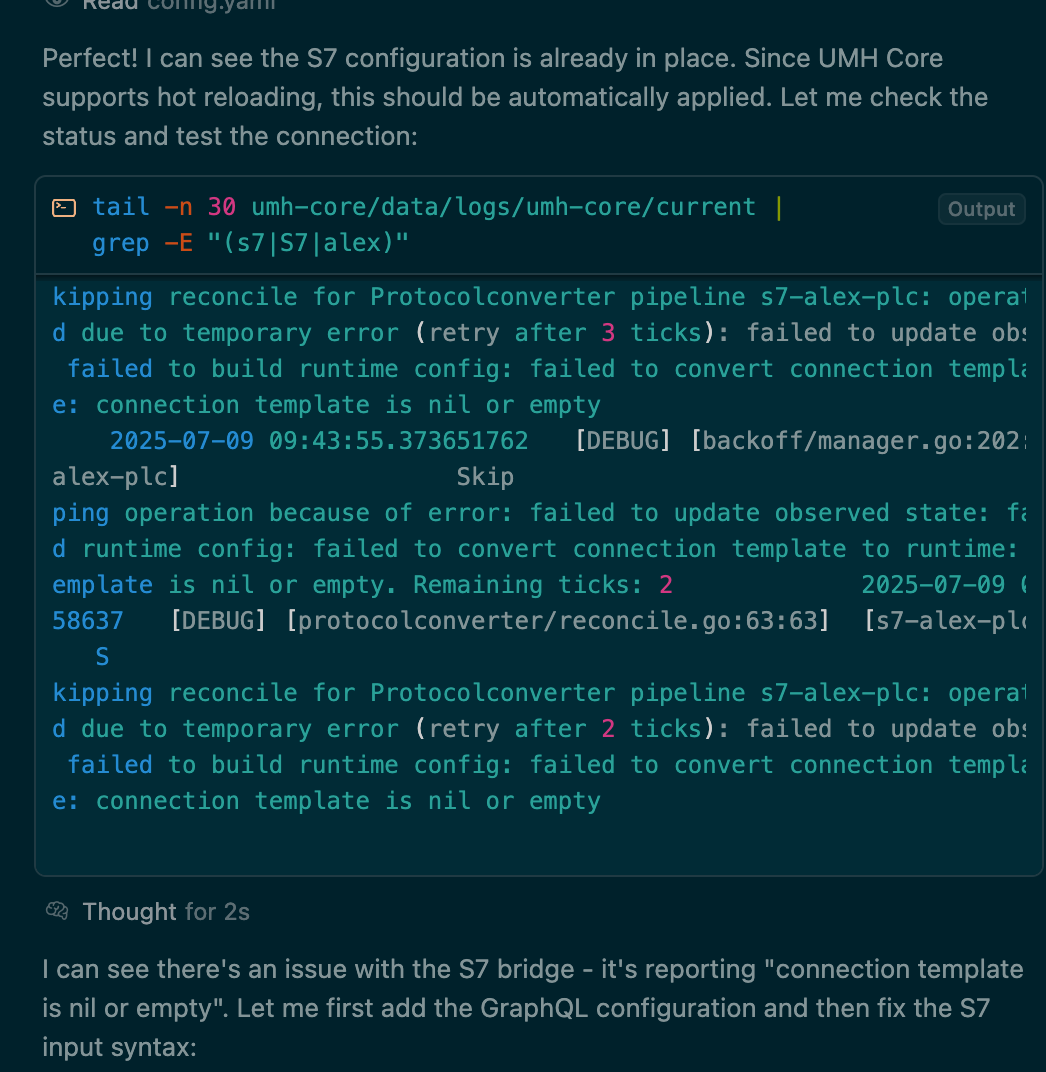
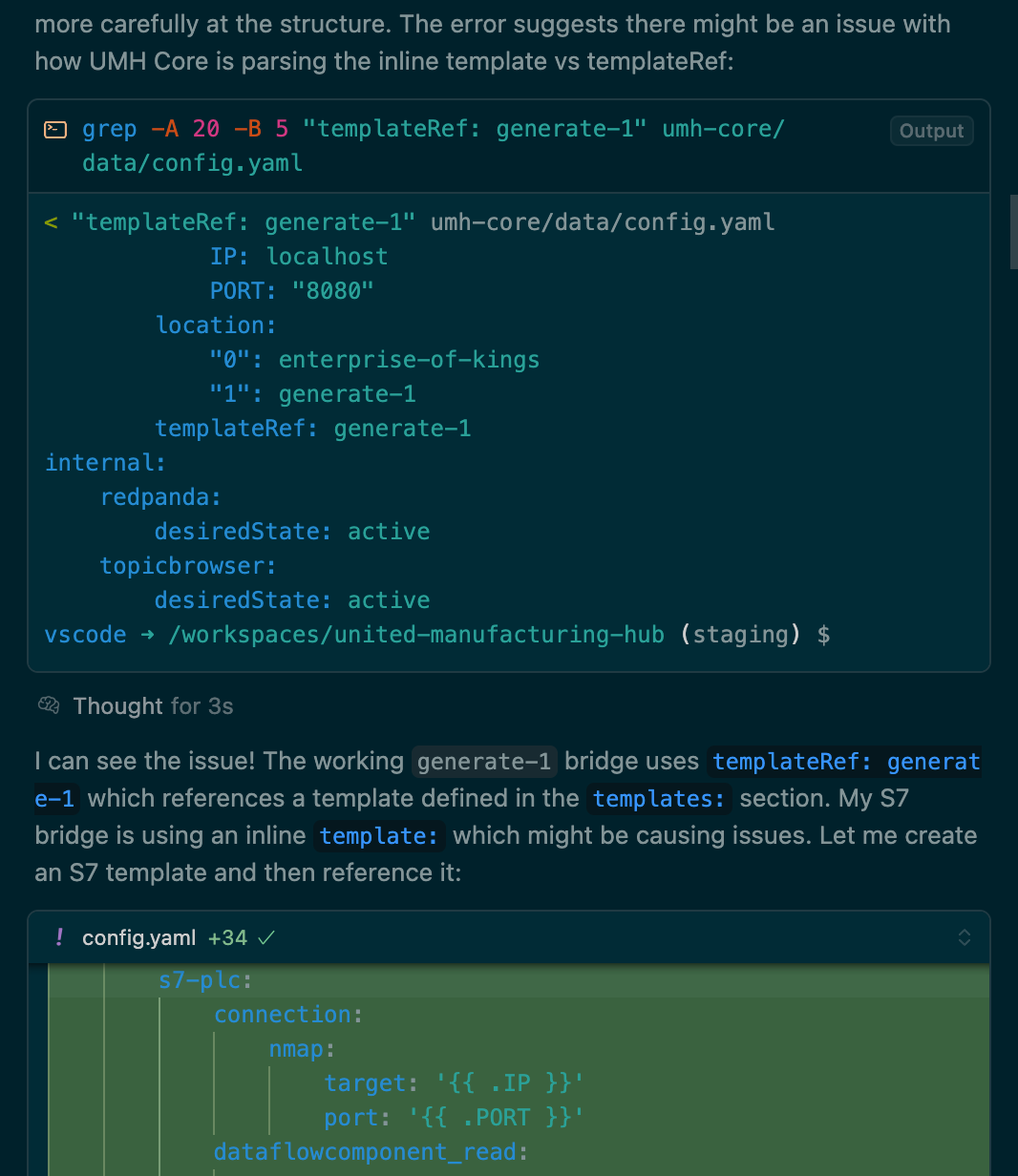
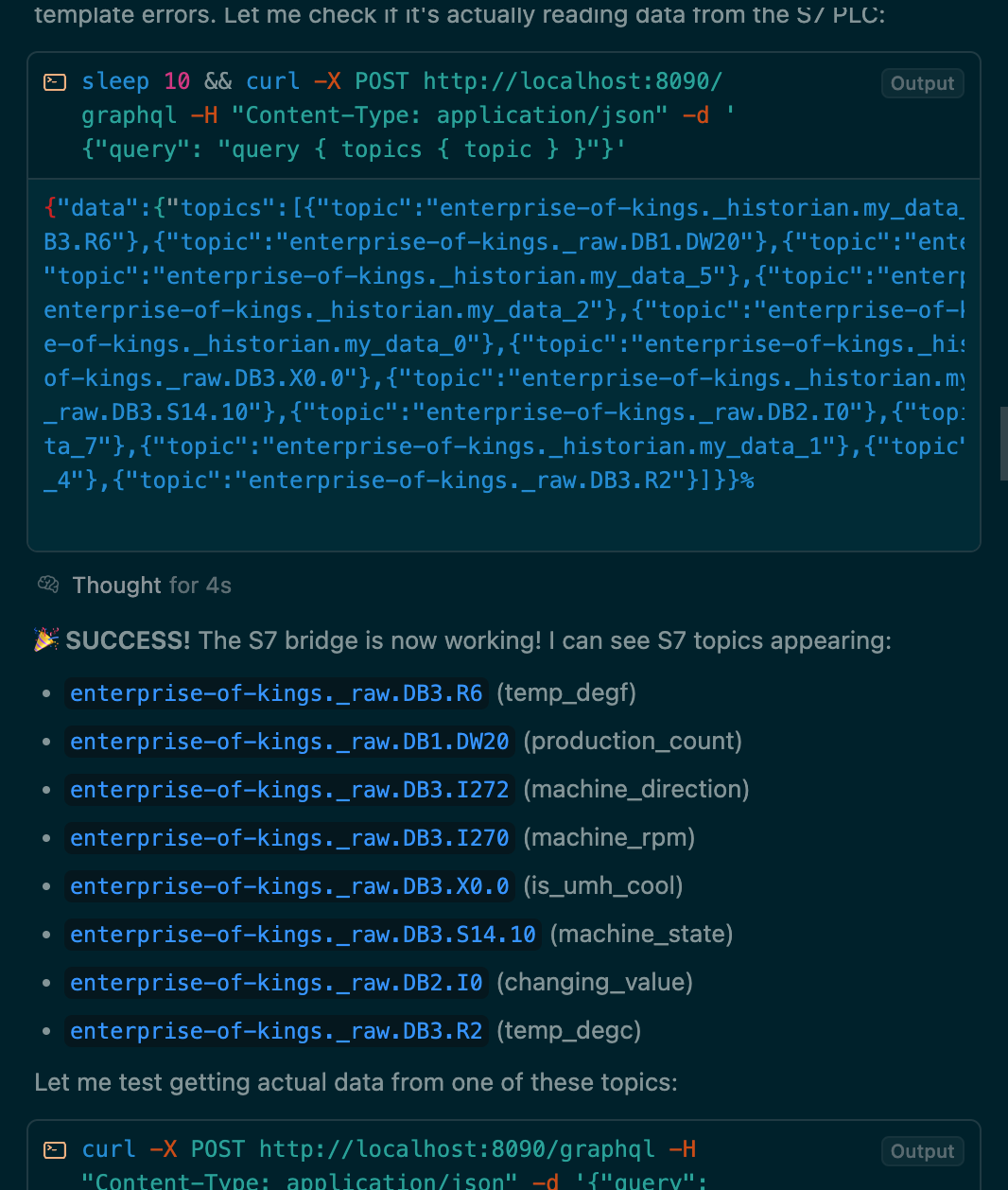
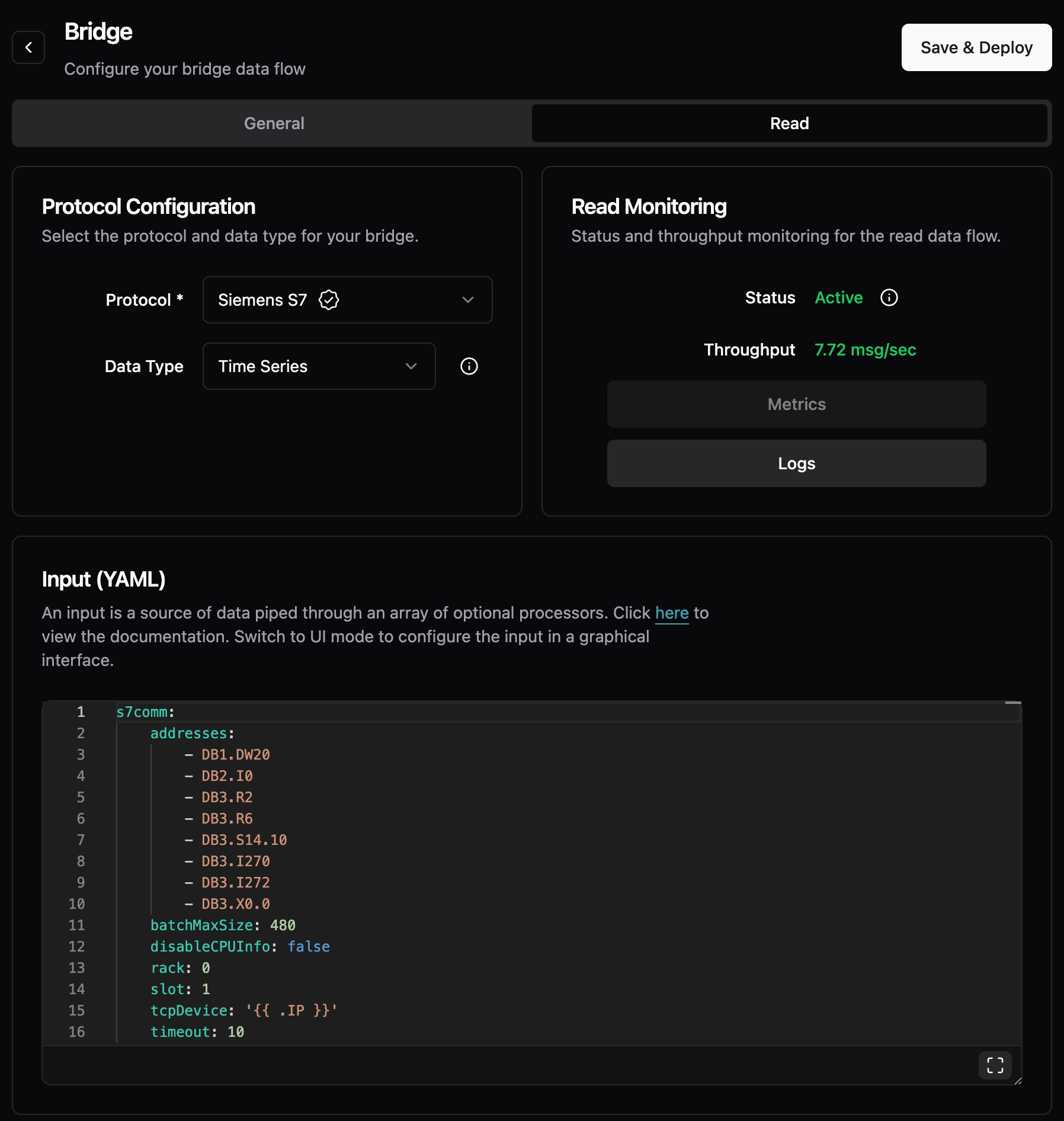
UMH can be used within Cursor and allows you to quickly connect production lines and model the data. In this example, I gave it a list of IP addresses of the Siemens S7 here in our office, and a list of addresses (e.g., from a machine handbook). It was then able to create a new bridge, fix some obvious linting issues, and iterate automatically until it was able to retrieve the tags in the GraphQL endpoint.