

In this webinar, we give a step-by-step walkthrough of United Manufacturing Hub (UMH) platform and cover key topics, including setting up virtual machines, implementing Unified Namespace, and leveraging tools like Grafana, OPC UA, and Modbus for data visualization and connectivity. Mateusz and Alexander demonstrate how to normalize machine data and create scalable, efficient systems using an event-driven architecture.
Whether you are starting with UMH or looking to find ways to optimize your industrial data operations with Unified Namespace, this session offers actionable insights with proven tools and techniques.
Webinar Agenda
- Overview of UMH platform and the UNSExplanation of Unified Namespace and its importance in industrial data operationsDiscussion on challenges with traditional shop floor data handling.Introduction to event-driven architectures and their benefits.
- Setting Up a Virtual Machine (VM)Step-by-step instructions for configuring a VM for industrial applications.Recommendations for operating systems and resource allocation.Explanation of software installation processes, including dependencies and setup.
- Connecting Data SourcesDemonstration of integrating various data protocols (OPC UA, Modbus, S7).Explanation of protocol converters and their role in IT/OT integration.Discussion on managing and troubleshooting data connections.
- Data Normalization and StructuringTechniques for standardizing machine data using unified namespaces.Practical use of templates for efficient data organization.Examples of data modeling to harmonize inputs from multiple sources.
- Data Visualization with GrafanaCreating dashboards for real-time and historical data visualization.Explanation of SQL queries for retrieving data.Demonstration of Grafana's capabilities for monitoring and reporting.
IT / OT Integration Platform for Industrial DataOps
Connect all your machines and systems with our Open-Source IT/OT Integration Platform to make all shop-floor data accessible at a single point.
Chapters
00:00 - Introduction and Objectives
03:42 - IT/OT and UNS Overview
08:42 - Setting up Virtual Machine
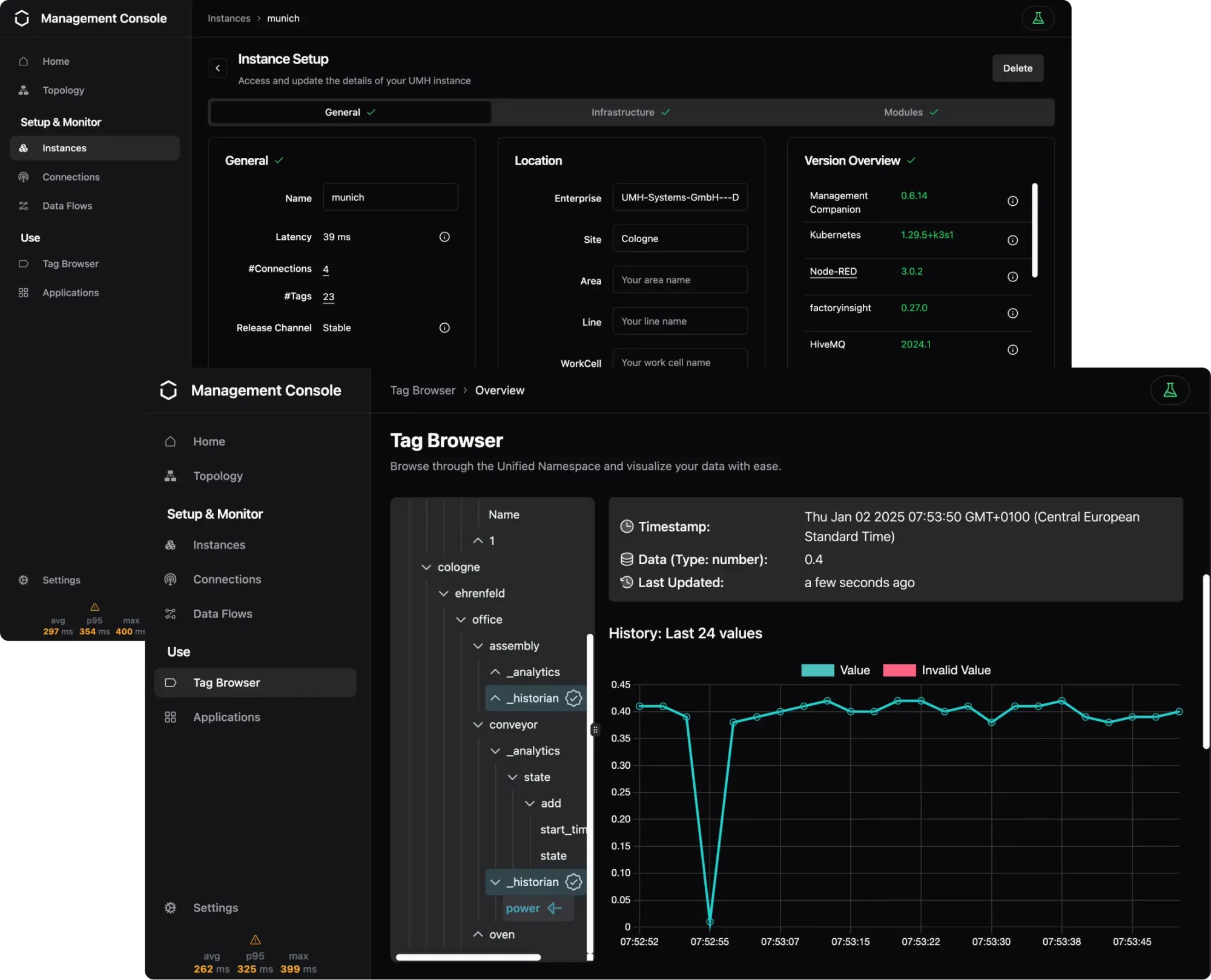
13:34 - UMH and Instance Setup
26:00 - Connecting to Data Sources
37:00 - Data Normalization and Structuring
41:57 - Data Visualization with Grafana
47:00 - Q&A and Participant Discussions
Transcript
Hello, everyone. My name is Matthias. I'm today supported by Alex. And this is our fourth webinar. I'm just going to give you a quick intro of what we want to do and achieve today. And then we pretty much give it a go. If you have any questions, please post them in the chat. Happy to answer them. We have a few of our colleagues in the chat and, of course, some of the community as well. More than happy to talk about any of your questions.
The agenda for today will be a quick intro to us both, where we come from, and what's our architecture and product. Then, we’re going to go into setting up a VM. Essentially, how to get started from zero: setting up the VM, installing, connecting different data sources, and visualizing your first data point. Afterward, we’ll have an offline Q&A to hear what you’re doing and address any remaining questions.
As background, I'm a mechanical engineer. After that, I worked in management consulting for five years, consulting various industries on digital transformation. Now, I’m at Hume as a Customer Success Manager, responsible for hands-on implementation—not just PowerPoint slides of these concepts. Today, I’m supported by my co-founder and CEO, Alex, who will introduce himself.
So, I’m Alex, co-founder and CEO, as already mentioned. I also have a mechanical engineering background. After university, I transitioned to system integration. Directly out of university, we had the idea of helping customers digitize their operations. We worked closely with Mateo in his prior role, and at some point, we decided to focus on automating repetitive tasks to enable more value creation. Today, we want to show you how to get started quickly because setting up from scratch often takes days or months before delivering any use case value, which can be frustrating. Our goal is to prove how fast and easy it can be.
Before we start, let me introduce the company behind it to ensure everyone is on the same page. We work on the interface between automation engineers, mechanics, electricians, and the IT teams who use data to drive use cases. We provide an IT/OT integration platform to combine data and technology to solve current and future business problems. We see industries transforming into tech companies, not necessarily by providing internet services like Netflix but by using digital technologies to solve their own challenges more effectively. This transformation, however, is not easy. It requires a journey, which is what we experienced as system integrators: connecting machines, providing dashboards, and making sense of data scattered across years of infrastructure.
Our approach is based on the Unified Namespace (UNS), which organizes all data in a central, event-driven architecture. This decouples data producers and consumers, making it easier to access and use data effectively. We also apply data modeling to harmonize data across different machine vendors, creating reusable, unified data products for your organization.
To achieve this, you need connectivity—whether it’s connecting to S7, Modbus, or other protocols—as well as tools to normalize and visualize the data. We’ll demonstrate this today. It’s not yet fully plug-and-play because deployments and maintenance still come with hidden complexities, such as managing containerized architectures like Kubernetes. We aim to simplify this process, making it usable for both IT and OT professionals.
Let’s start with the basics. We’re setting up a local Proxmox server, creating a new instance, and selecting the operating system. We’re using Rocky Linux 9.4, which mirrors Red Hat Enterprise Linux, providing a stable and enterprise-compatible base. It’s lightweight yet powerful, with features tailored for edge and server-based deployments.
After configuring the VM with sufficient resources (e.g., 16GB of RAM, four cores, and 250GB SSD), we’ll install the software stack. This includes everything from the database to the event broker and visualization tools. The stack is designed to handle complex workloads, such as deploying hundreds of containers while leaving enough headroom for future expansions.
Once the VM is ready, we’ll demonstrate how to install our management console and create an instance using a single command. This approach simplifies the setup of complex systems like Kubernetes, Kafka, and Grafana. You don’t need to be an expert; the console manages dependencies and ensures everything works seamlessly together.
Next, we’ll connect data sources. We’ll show how to integrate protocols like OPC UA, Modbus, and S7. For example, we’ll use the OPC UA browser feature to browse and select specific machine data points. This eliminates the need for on-site configuration, enabling remote management from your office. Data points can be mapped and normalized using templates, making them intuitive and reusable across systems.
For visualization, we’ll use Grafana. The console automatically stores data in a timescale database, providing easy access via SQL queries. Dashboards can display real-time and historical data, aggregated or detailed as needed. This flexibility is key for monitoring KPIs, analyzing trends, and improving decision-making.
Finally, we’ll discuss advanced use cases, such as integrating operator inputs into dashboards. For example, an operator can log reasons for machine stops, adding valuable context to the data. These inputs can be analyzed later to improve processes and reduce downtime.
Thank you for attending. Please feel free to ask questions during the Q&A session or reach out via our community Discord channel. We’re here to support you in your digital transformation journey and look forward to your feedback.
Thank you so much. So without further ado, let’s jump into the basics. I would like to start really from zero. I’ll explain what to do with the system, why we have specific OS requirements, and much more. Over here, we have our local Proxmox server. I’m creating a new instance, selecting an operating system—in this case, Rocky Linux 9.4. I prefer using the full image because it includes nano and other tools for troubleshooting, though the minimal image also works.
Some people might be surprised by the resource requirements: 16GB of RAM, four cores, and a 250GB SSD. While it seems heavy, this setup ensures sufficient resources for deploying and running hundreds of containers, which include technologies like databases, message brokers, and streaming platforms. Starting with a high baseline also provides enough headroom for future expansions.
Once the instance is created, we’ll install the management console. The setup involves running a single command, simplifying the installation of tools like Kubernetes and Kafka. This command fetches all necessary dependencies, configures the system, and deploys the stack automatically. The result is a fully functional environment that is easy to maintain.
After installation, we’ll connect data sources. For example, I’ll demonstrate how to use the OPC UA browser feature to discover available nodes from a machine. This tool eliminates the need for on-site configuration, enabling remote access to machine data. Specific nodes or entire folders can be subscribed to, depending on the use case.
In the next step, we’ll focus on normalizing the data. Using templates, we’ll map raw data points to meaningful identifiers. For instance, instead of “DB 0.2.1,” a temperature sensor might be labeled “Temperature.” This makes the data intuitive for engineers and ensures consistency across systems.
For visualization, we’ll use Grafana. The unified namespace stores data in a timescale database, providing easy access via SQL queries. Dashboards can display aggregated or real-time data, depending on the requirements. For example, operators can view live machine states and log reasons for downtime directly into the system, adding valuable context to the data.
Throughout the webinar, we’ll also address questions from participants. We’ll cover topics like compatibility with edge devices, optimizing system performance, and best practices for managing deployments. Our goal is to ensure everyone leaves with a clear understanding of how to start and scale their IT/OT integration journey.
Thank you again for joining us. If you have further questions or need support, please connect with us on our community Discord channel. We’re excited to hear about your use cases and help you succeed in your digital transformation efforts.


