

How Kafka works
The principle is similar to the one of an MQTT broker:
- There are consumers and producers (both are also called clients) with a broker in the middle
- Messages, or in Kafka terminology events, are published by a producer to a topic and can then be consumed by another microservice
The difference is that each event is written into a log to disk first. This sounds like a small detail at the beginning, but because of it Kafka can guarantee you message ordering, zero message loss and efficient exactly-once processing even in the harshest environments.
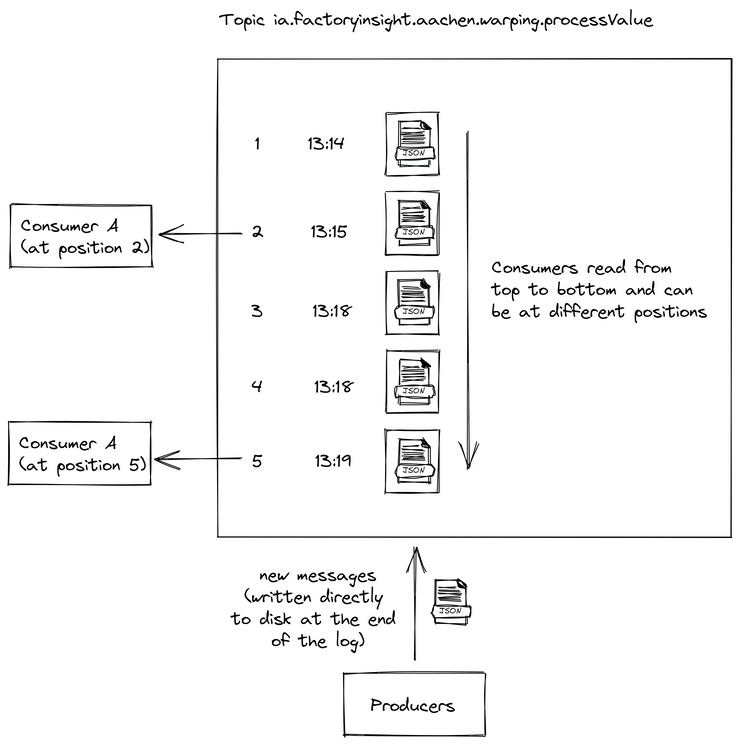
To learn more about what makes Kafka great and what its use cases might be, we recommend reading our blog post article regarding United Manufacturing Hub’s decisions on using MQTT and Kafka as well as watching the following videos.
This first video explains very well which use cases Kafka has and for which use cases it is helpful. To reiterate, some of those are:
- decoupling system dependencies, as the sub/pub architecture eliminates the use for integration
- messaging
- location tracking
The video also goes over the four important Kafka APIs
- Producer API, which allows to produce streams of data with topics. Like described above, these can be saved to disk
- Consumer API, which allows to subscribe toward topics in real time or even old saved data of the subscribed topics
- Streams API, which allows consumes from topics, transforms data in a certain manner and then produce the transformed data, this is fairly unique to kafka and makes it especially powerful
- Connector API, which allows developers to write connectors, reusable producers and consumers, which just need to be configured
This video is way more technical and does not go over Kafkas functionalities but much more about how Kafka leverages smart algorithms to increase its ability to process large amounts of data without delays.


