See https://learn.umh.app/lesson/data-modeling-in-the-unified-namespace-mqtt-kafka/ for the updated articles
This article is a working draft for our new MQTT / Kafka datamodel. Feedback via our Discord Channel is greatly appreciated.
Current Unified Namespace
The current topic structure uses a format like ia/<customer>/<location>/<asset>/<tag>
Proposed Unified Namespace
We will change it to a more ISA95 compliant format. We propose:
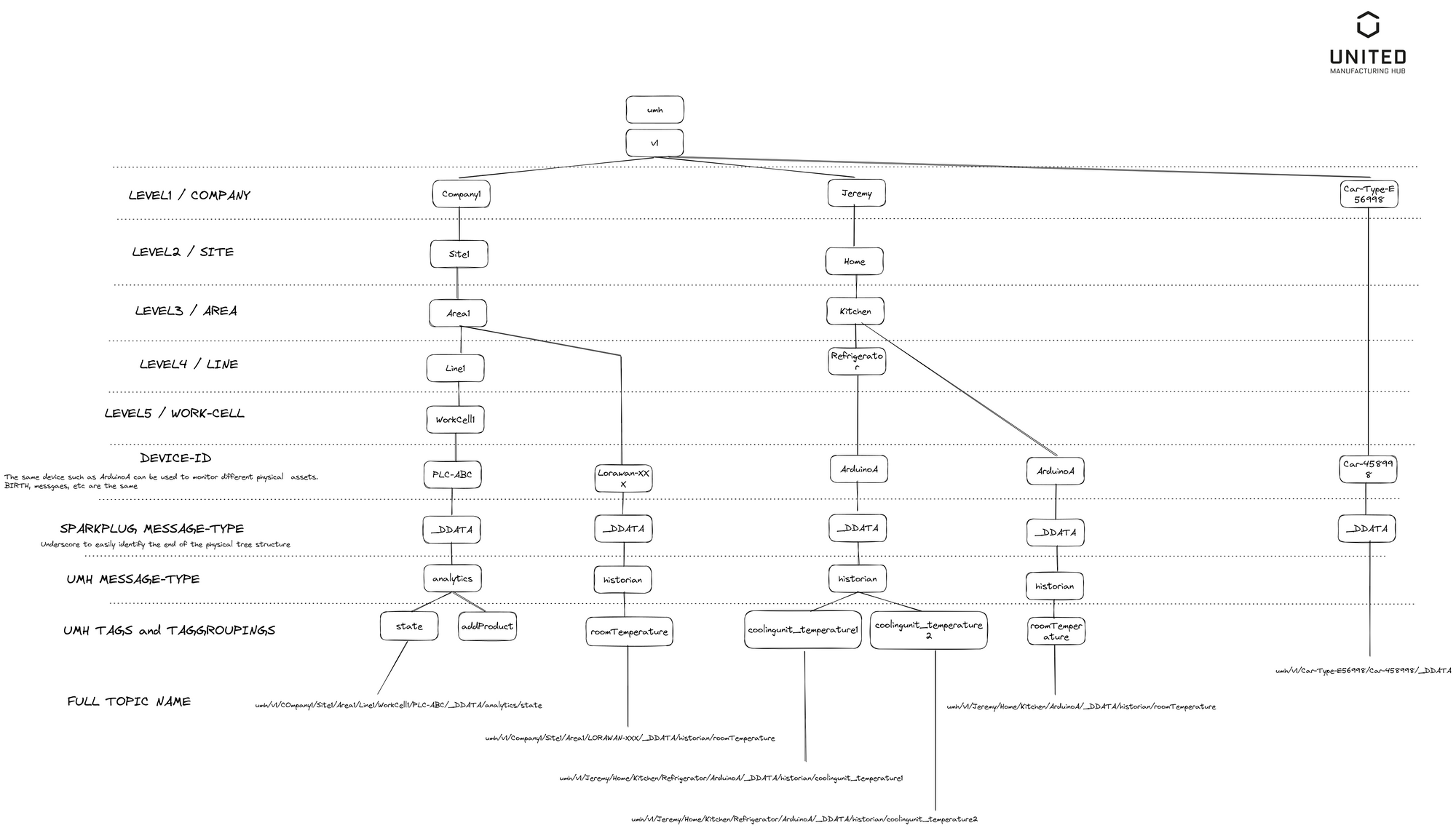
umh/v1/<enterprise>/<site>/<area>/<productionLine>/<workCell>/<tagGroup>/<tag>
umh/v1/enterprise/site
The first part umh/v1 allows versioning of the datamodel and changes in the future. customer equals to enterprise and location equals to site.
area/productionLine
New are the new grouping functionalities areaand productionLine, which will help in structuring large-scale deployments. Also it will enable some additional KPIs like “bottleneck Machine”, which will automatically identify via still-to-be-defined-methods the bottleneck from all available workCell s in a productionLine
workCell
asset now equals to workCell
If the workCell has the same name as the productionLine, then the entire productionLine is meant. This could be used in the future to introduce additional functionality like “automatedBottleneckDetection”
workCell to the same name for productionLine. In the frontend, it will then be shown immediately under productionLine. The same for area, site and enterprise.Example:
umh/v1/test-customer/aachen/aachen/aachen/aachen/custom/weathertagGroup/tag
New are also now the grouping functionality tagGroup as well as the naming of the tags.
There are three available tagGroups (see also further down for more infos on how to add your own ones):
analyticshistorianevent
The main reason for using tagGroup is a more intuitive behavior of the stack.
Messages send to historian qual to messages send in the previous datamodel to processValue This should be used when you want to add your own tags to the UMH and use the Historian / Data Storage feature of the UMH. By using underscores in the tagname, you can group them and they will be shown as a separate group in Grafana. For example: temperatures_head and temperatures_bottom will be shown together as a group called temperatures
Messages send to analytics need to have a very specific payload. When messages are send here, they will be automatically processed and used for the Shopfloor KPI / Analytics Feature of the UMH and other messages will be derived from it. For example when sending a count message, the backend (in this case factoryinsight) will automatically derive the production speed from it.
The exact message types are typically the same from the previous datamodel, but they might have a slighly changed name to be more ISA95 conform:
- job/add —>
addOrder- job-id
- product-type
- target-amount (TODO)
- job/delete
- job-id
- job/start —>
startOrder- job-id
- timestamp-begin
- job/end —>
endOrder- job-id
- timestamp-end
- shift/add —>
addShift- timestamp-begin
- timestamp-end
- shift/delete —>
deleteShift- timestamp-begin
- product-type/add —>
addProduct- product-id
- cycle-time-in-seconds
- product/add —>
count- product-type-id
- We do not know the product-type-id
- It is already specified in the job
- But when inserting into database, we need to know it
- timestamp-end
- timestamp-end is the “primary key” to identify a product for a workCell
- note: there can only be one product produced per millisecond.
- (optional) id
- (optional) timestamp-begin
- (optional) total-amount
- (optional) scrap
- product-type-id
- product/overwrite—>
modifyProducedPieces- timestamp-end
- (optional) id
- (optional) timestamp-begin
- (optional) total-amount
- (optional) scrap
- state/add —>
state- timestamp-begin
- state
- see also our state list, that one stays the same
- state/overwrite—>
modifyState- timestamp-begin
- timestamp-end
- state
- state/activity —>
activity- timestamp-begin
- activity
- note: there needs to be a microservice autoamtically calculating the state from activity and detectedAnomaly
- state/reason —>
detectedAnomaly- timestamp-begin
- reason
- note: there needs to be a microservice autoamtically calculating the state from activity and detectedAnomaly
- Items related to digital shadow are removed for now (
uniqueProduct,scrapUniqueProduct,addParentToChildproductTag,productTagString) - Recommendation is also removed for now (
recommendation)
Messages send to event will be bridged across MQTT and Kafka according to the Unified Namespace feature, but otherwise not processed by any microservice. They will not be send to the server (kafka-bridge) or stored (kafka-to-postgresql). Therefore, the messages can have any format. It should be used whenever external services can send data to MQTT, but you cannot adjust the payload. With this, it is possible to send the data to MQTT and then convert it to either historian or analytics
How to add your own tagGroups?
You can basically just create a new tagGroup and the data will be bridged between MQTT and Kafka and between Kafka brokers, but it will not be checked on any schema. You could add something like maintenance or plm and then start sending data in your own data model towards these topics.
Why not SparkplugB?
We have already explained our general dislike of SparkplugB here: https://learn.umh.app/lesson/introduction-into-it-ot-mqtt/#sparkplug-b
If SparkplugB would support flexible topic structures, we could compromise by leveraging a SparkplugB prefix followed by our proposed datamodel.
Potentially SparkplugB compatible