Benthos is a stream processing tool that is designed to make common data engineering tasks such as transformations, integrations, and multiplexing easy to perform and manage. It uses declarative, unit-testable configuration, allowing users to easily adapt their data pipelines as requirements change. Benthos is able to connect to a wide range of sources and sinks, and has a wide range of processors and a “lit mapping language” built-in. It also offers a visual web application called Benthos Studio that allows users to create, edit, and test configs. Benthos is designed to be reliable, with an in-process transaction model and no need for disk-persisted state, and it’s easy to deploy and scale. Additionally, it can be extended using plugins written in Go or by running them as subprocesses.
It is very easy to integrate with the United Manufacturing Hub.
Requirements
- One installed UMH instance
Instructions
- Open the UMH instance in UMHLens / OpenLens
- Add a new resource
- Paste in below Kubernetes files and press “Create & Close”
- A new pod should have been created and running
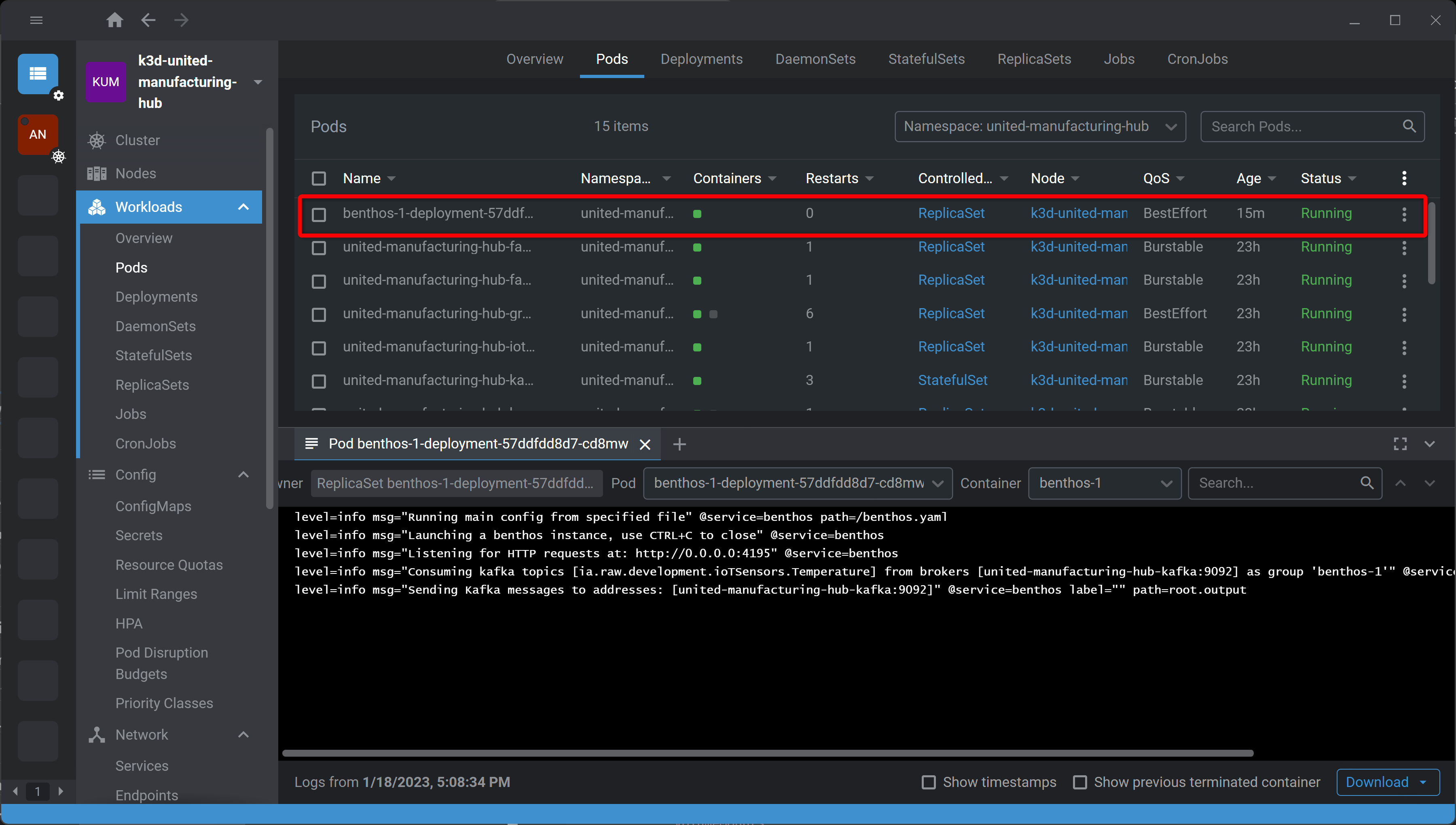
By default, this flow will take the temperature values from the included simulator ia.raw.development.ioTSensors.Temperature and convert it to the UMH datamodel by changing the payload and sending it back to ia.factoryinsight.munich.ioTSensors.processValue.Temperature.
To change the flow, you just need to change the content of the benthos.yaml file, which you can find in the ConfigMap ‘benthos-1-config’. For more information, please take a look into the official benthos documentation: https://www.benthos.dev/
Kubernetes files
apiVersion: v1
kind: ConfigMap
metadata:
name: benthos-1-config
namespace: united-manufacturing-hub
labels:
app: benthos-1
data:
benthos.yaml: |-
input:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topics:
- ia.raw.development.ioTSensors.Temperature
consumer_group: "benthos-1"
pipeline:
processors:
- bloblang: |
let temperature = content().string()
let timestamp = (timestamp_unix_nano() / 1000000).floor()
root = {
"timestamp_ms": $timestamp,
"temperature": $temperature
}
output:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topic: ia.factoryinsight.munich.ioTSensors.processValue.Temperature
client_id: benthos-1
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: benthos-1-deployment
namespace: united-manufacturing-hub
labels:
app: benthos-1
spec:
replicas: 1
selector:
matchLabels:
app: benthos-1
template:
metadata:
labels:
app: benthos-1
spec:
containers:
- name: benthos-1
image: "jeffail/benthos:latest"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 4195
protocol: TCP
livenessProbe:
httpGet:
path: /ping
port: http
readinessProbe:
httpGet:
path: /ready
port: http
volumeMounts:
- name: config
mountPath: "/benthos.yaml"
subPath: "benthos.yaml"
readOnly: true
volumes:
- name: config
configMap:
name: benthos-1-configOther examples
Aggregating the image classification from two different topic
input:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topics:
- ia.raw.audio.spectogram.2.classification
- ia.raw.audio.spectogram.1.classification
consumer_group: "benthos-results-aggregator"
pipeline:
processors:
- switch:
- check: meta("kafka_topic") == "ia.raw.audio.spectogram.1.classification"
processors:
- branch:
request_map: root.classification = this."classification_result"."class_label"
processors:
- cache:
resource: memorycache
operator: set
key: accelerometer-classification
value: ${!json("classification")}
fallthrough: false
- check: meta("kafka_topic") == "ia.raw.audio.spectogram.2.classification"
processors:
- branch:
request_map: root.classification = this."classification_result"."class_label"
processors:
- cache:
resource: memorycache
operator: set
key: microphone-classification
value: ${!json("classification")}
fallthrough: false
- check: ""
processors:
- log:
level: INFO
- mapping: root = deleted()
fallthrough: true
- branch:
request_map: ""
processors:
- cache:
resource: memorycache
operator: get
key: accelerometer-classification
result_map: root.accelerometer_classification = content().string()
- branch:
processors:
- cache:
resource: memorycache
operator: get
key: microphone-classification
result_map: root.microphone_classification = content().string()
- bloblang: |-
let finalClassification = match {
this."accelerometer_classification" == "Machine-off" || this."microphone_classification" == "Machine-off" => "Machine-off",
this."accelerometer_classification" == "Machine-on" && this."microphone_classification" == "good" => "good",
this."accelerometer_classification" == "Machine-on" && this."microphone_classification" == "medium" => "medium",
this."accelerometer_classification" == "Machine-on" && this."microphone_classification" == "bad" => "bad",
_ => "Machine-off"
}
root = {
"timestamp_ms": this."timestamp_ms",
"classification": $finalClassification
}
output:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topic: ia.factoryinsight.aachen.warping.processValueString.classification
client_id: benthos-results-aggregator
metadata:
exclude_prefixes: ["kafka_"]
cache_resources:
- label: memorycache
memory:
default_ttl: 5m
compaction_interval: 60s
shards: 1
Measuring the average message processing time
input:
kafka_franz:
seed_brokers:
- united-manufacturing-hub-kafka:9092
topics:
- ia\.factoryinsight\..*
- ia.raw.audio.spectogram.1
- ia.raw.audio.spectogram.2
- ia.raw.audio.spectogram.1.classification
- ia.raw.audio.spectogram.2.classification
regexp_topics: true
consumer_group: "benthos-latency-measurement"
pipeline:
processors:
- try:
- mapping: |
# Ignore unstructured data
root = this.catch(deleted())
- mapping: |
# Ignore message if it does not have a timestamp
root = if !this.exists("timestamp_ms") { deleted() }
- bloblang: |
let currentTimestamp = (timestamp_unix_nano() / 1000000).floor()
let originalTimestamp = this."timestamp_ms".number()
let latency = $currentTimestamp - $originalTimestamp
let processValueName = meta("kafka_topic").replace_all_many([".","_"])
root = {
"timestamp_ms": $currentTimestamp,
$processValueName: $latency
}
output:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topic: ia.performance.performance.latency.processValue
client_id: benthos-latency-measurement
metadata:
exclude_prefixes: ["kafka_"]
Fetching images from a thermal camera and pushing it to Kafka
input:
http_client:
url: http://172.16.42.20/snapshot.jpg
verb: GET
basic_auth:
enabled: true
username: admin
password: admin
rate_limit: webcam_frequency
timeout: 5s
retry_period: 1s
max_retry_backoff: 300s
retries: 3
pipeline:
processors:
- bloblang: |
let jpgImageAsBase64 = content().encode("base64").string()
let timestamp = (timestamp_unix_nano() / 1000000).floor()
root = {
"timestamp_ms": $timestamp,
"imageAsBase64EncodedJPG": $jpgImageAsBase64
}
output:
kafka:
addresses:
- united-manufacturing-hub-kafka:9092
topic: ia.raw.flixax8
client_id: benthos_flixax8
batching:
period: 1s
rate_limit_resources:
- label: webcam_frequency
local:
count: 1
interval: 1sCombine messages coming from OPC-UA into a single JSON payload
pipeline:
processors:
- bloblang: |
let newName = match {
meta("opcua_path") == "ns_4_i_3" => "machineNumber",
meta("opcua_path") == "ns_4_i4" => "dataSetNumber",
=> meta("opcua_path")
}
root = {
$newName: content().string(),
}
- archive:
format: json_array
- bloblang: |
root = this.append({"timestamp_mx":timestamp_unix()})
- bloblang: |
root = this.squash() Thank you DanielH for providing this snippet.