

Most MQTT explanations suck - they are either confusing or too technical or skip the big-picture context entirely. You deserve better. This guide aims to clarify what MQTT is, how it works, and how it fits into the overall context of IT and OT
After years of building Industrial IoT solutions and speaking with MQTT and AMQP committee members, I realized how often MQTT is misapplied, which leads to lost data and messy connections between systems.
In the end, MQTT is great for IoT telemetry data, but its simplicity comes with serious drawbacks for typical manufacturing use-cases.
This article is divided into three main chapters:
- Chapter A: What is MQTT?
- Chapter B: MQTT is Ideal for IoT Telemetry Data
- Chapter C: MQTT Can Be Problematic in Certain Use Cases
Learning about MQTT’s limits now can save you, and your team, from months of troubleshooting - whether you are using MQTT in the field of IoT or as a Unified Namespace in manufacturing.
But it doesn't matter how hard most MQTT explanations suck, OPC UA sucks harder. Let's get started:
Chapter A: What is MQTT?
MQTT (Message Queue Telemetry Transport) is a protocol designed to exchange messages between devices and applications. For simplicity, we will refer to both types of endpoints as “devices” throughout this article. MQTT uses a publish/subscribe architecture, where devices communicate through a central hub called a message broker.
In this architecture, devices that produce data are called publishers. They send messages to the message broker without needing to know which devices will receive them. Devices that consume data are called subscribers. They tell the message broker which messages they're interested in, and the broker delivers those messages to them. Publishers send their messages to specific topics, which act as routing labels—much like folders in a file system.
Small disclaimer: MQTT may not always be the best choice, but we’ll get to that in Chapter C.
A.1 The Architectural Reasoning Behind MQTT
For the IT/OT architect, it is essential to understand why MQTT’s publish/subscribe is chosen over other communication methods:
- It avoids spaghetti diagrams and reduces integration overhead: In traditional direct device-to-device connections, adding or removing a device often requires reconfiguring the connections of the other devices. MQTT’s publish/subscribe architecture avoids this by using a central broker, thereby simplifying the network.
- It supports real-time data exchange: Unlike databases that require constant polling (so request / response pattern which introduces latency), MQTT’s publish-subscribe enables the broker to push messages to subscribers as soon as they are published.
Among publish/subscribe protocols, MQTT stands out for its simplicity and lightweight design. It's optimized for devices with limited processing power and for environments where network connections might be intermittent or unreliable—conditions often found in IoT applications like remote sensors and embedded systems.
While there are other protocols and architectures available, we’ll explore these comparisons in Chapter B.
A.2 How It Works
Think of MQTT like a news agency:
- Reporters (Publishers): They write stories (messages) and send them to a central office (Message Broker) with labels such as
world/germany/technology/mqtt. They don’t need to know which newspapers (subscribers) will pick up these stories. - Central Office (Message Broker): It keeps track of what each newspaper is interested in, and routes the incoming stories to that newspaper.
- Newspapers (Subscribers): They subscribe to certain categories, such as
world/germany/technology/#. Whenever a reporter sends a matching story to the central office, that newspaper receives it.
Similarly, in MQTT:
- Publishers don’t worry about which subscribers need their data.
- Subscribers tell the broker, “I want data labeled X or Y.”
- The Broker routes each message to the right subscribers.
In MQTT terms, each category/label is called a topic. Topics can have wildcards (like +/+/temperature or world/germany/technology/#) so a device can receive many related messages using one subscription. This keeps your system flexible and prevents you from having to manually link devices one by one.
A.3 MQTT in Practice
In many of the most popular Unified Namespace (UNS) deployments in manufacturing, MQTT serves as the backbone—funneling data from sensors, PLCs, and other devices into a centralized data pool for easy access.
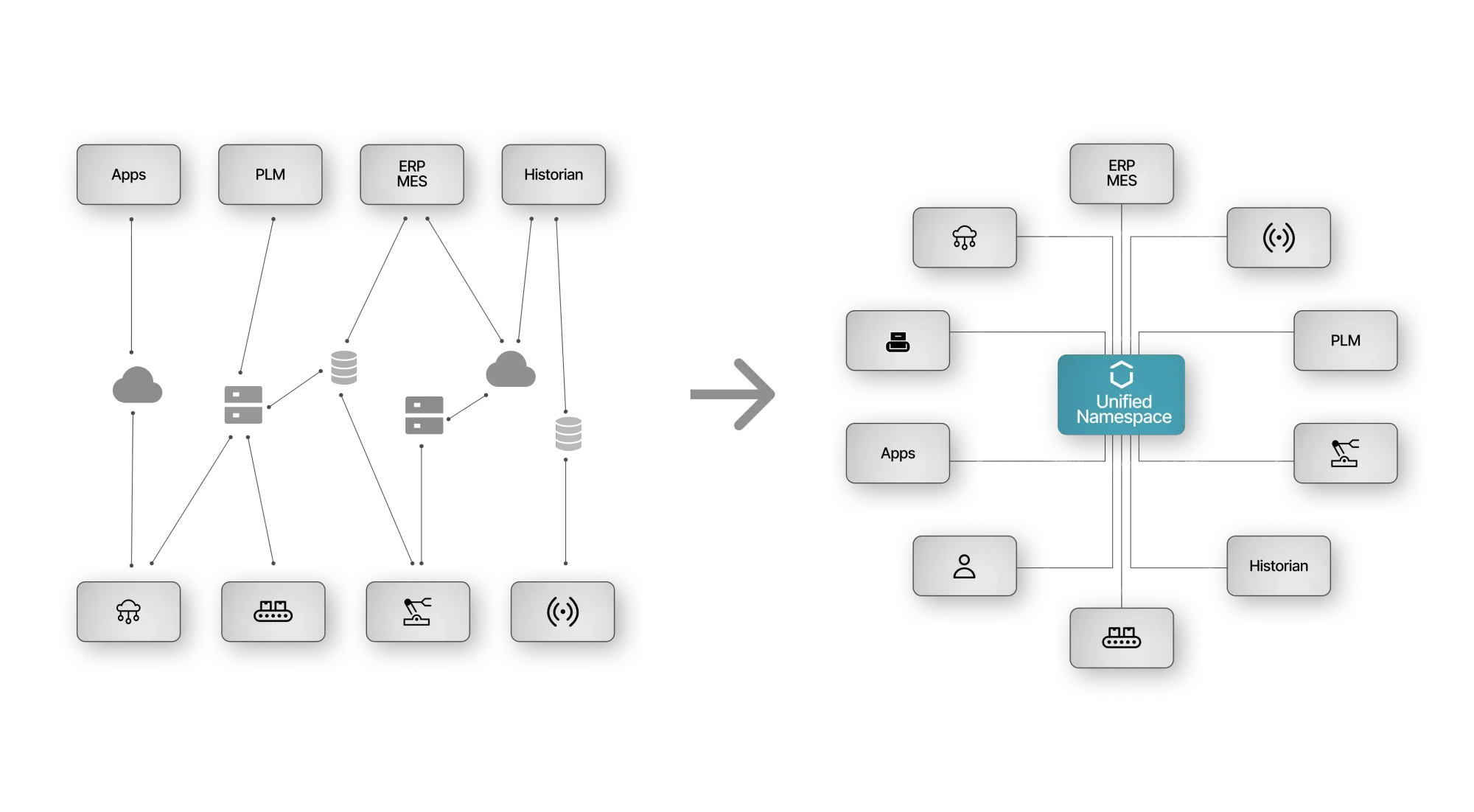
In practice, implementing MQTT involves:
- Set up a message broker: Choose a broker that suits your needs—whether open-source or commercial—as compared in our previous article.
- Configure OT devices to publish or subscribe: Devices such as Programmable Logic Controllers (PLCs, industrial computers for controlling machines) or Automated guided vehicles (AGVs, small transport robots in the factory) can be set up to publish data directly to the broker.
- Use MQTT client libraries in IT: With client libraries available in languages such as Python, Go, JavaScript, and more, developers can quickly integrate MQTT into various applications.
A.4 Summary
MQTT is a lightweight, publish/subscribe protocol ideally suited for IoT environments. Its ability to avoid complex connections (spaghetti diagrams) and provide real-time data exchange is due to its fundamental separation (decoupling) of publishers and subscribers. This architectural approach not only simplifies network design but also provides the foundation for more advanced architectures, such as a Unified Namespace, which we will explore in more detail in the following chapters.
With this foundation in place, we can now explore how MQTT compares to other architectural approaches and protocols. In Chapter B: MQTT is ideal for IoT telemetry data, we'll expand on these comparisons to provide a broader context for MQTT's role in the IoT landscape.
Chapter B: MQTT is Ideal for IoT Telemetry Data
MQTT is ideal for IoT telemetry data due to its unique advantages in architecture, resource efficiency, network handling, and ease of integration.
Telemetry data refers to information automatically gathered by sensors—often at regular intervals—and sent from remote or distributed devices for monitoring and analysis. It typically takes the form of time-stamped (time-series) measurements, such as temperature readings or machine performance metrics.
This section explores:
- How MQTT’s architecture (publish/subscribe) meets IoT’s need for decoupled, low-latency data flow.
- How MQTT compares to other IoT protocols (such as AMQP, CoAP), underscoring its place as the go-to standard.
- How MQTT stacks up against data-center-grade messaging systems (Kafka, RabbitMQ)—and why its lightweight design is still ideal for many edge scenarios.
B.1 Architectural Advantages of MQTT's Publish/Subscribe Model
First, let’s see how MQTT’s publish/subscribe architecture perfectly suits IoT’s need for decoupled, asynchronous data flow.
In MQTT's publish/subscribe model, devices communicate by sending messages through a message broker. This approach allows for asynchronous, decoupled communication, offering benefits such as scalability and flexible routing.
B.1.1 How MQTT’s Pub/Sub Decouples IoT Systems
MQTT’s architecture naturally decouples the concerns of data production and consumption. This decoupling occurs in three dimensions: [1]:
- Space Decoupling: Publishers and subscribers do not need to know each other's identity or network location. New devices can be added or removed without disrupting existing communications.
- Time Decoupling: Publishers and subscribers do not need to interact with the system at the same time. Messages are sent and received asynchronously. This approach allows devices to go offline without affecting others—critical for unreliable networks.
- Synchronization Decoupling: Operations are asynchronous; publishers are not blocked when publishing messages, allowing efficient resource utilization.
In practice, this means you can deploy new sensors without telling existing machines—everyone just connects to the broker.
Limitation:
- Increased Complexity by Adding Another Component: Introducing a central message broker adds another layer to the architecture. This additional component may require careful setup, monitoring, and maintenance. However, the scalability and flexibility benefits generally justify this added complexity.
B.1.2 Why Async Message Passing Outperforms Databases and Service Calls
To understand why MQTT's architecture is well suited for IoT telemetry data, it's helpful to explore other common approaches to data communication. Martin Kleppmann, in his book Designing Data-Intensive Applications [2], categorizes communication methods into:
- Dataflow Through Databases
- Dataflow Through Service Calls
- Dataflow Through Asynchronous Message Passing
| Dataflow Through Service Calls | Dataflow Through Databases | Dataflow Through Asynchronous Message Passing |
|---|---|---|
| HTTP/REST | SQL/NoSQL | Smart Brokers: MQTT, AMQP, NATS |
| CoAP | Dumb Brokers: Kafka |
B.1.1.1 Dataflow Through Databases
In this approach, applications communicate by reading from and writing to a shared database. The database acts as an intermediary, and processes read data that was previously written.
- Advantages:
- Simple implementation for storing and retrieving data.
- Limitations:
- Not Suitable for Real-Time Communication: Databases are optimized for data consistency and durability, often using mechanisms such as transactions and write-ahead logging (WAL). These features introduce latency due to disk I/O and processing overhead, making databases less ideal for the low-latency communication required by IoT telemetry data.
- Polling Overhead: Databases typically require polling (asking proactively) to detect updates. This can waste resources if queries outpace actual data changes or delay notification if the polling interval is too slow.
Disclaimer: Yes, there are such things as “Streaming Databases” that claim to be a database for real-time data, but the underlying architecture of systems like ksqlDB is based on asynchronous message passing rather than traditional database algorithms. They are termed “databases” because they provide a familiar SQL interface, but fundamentally operate on continuous, log-structured data streams (e.g., Kafka’s append-only commit log) rather than the static, index-based storage typical of traditional databases.
B.1.1.2 Dataflow Through Service Calls
In this model, communication takes place through direct remote procedure calls (RPCs), commonly using protocols such as REST or SOAP. Clients make requests to servers, which process them and return responses.
- Advantages:
- Familiar and robust, especially for synchronous interactions.
- Limitations:
- Tight Coupling: Direct connections create dependencies between clients and servers, making the system less flexible and harder to scale.
- Complexity: Direct service-to-service communication can result in complex, tangled architectures, that require overhead similar to "spaghetti diagrams"
B.1.1.3 Dataflow Through Asynchronous Message Passing
In the publish/subscribe model, with message brokers acting as intermediaries, devices communicate asynchronously, reducing direct dependencies. This communication model can be split into smart and dumb brokers^Selecting the Right Message Brokers based on the intelligence on the broker.
- Dumb Brokers: Brokers like Kafka store messages in a persistent log for later consumption (see also our detailed explanation here in detail of how Kafka works here).
- Advantages:
- High Throughput and Durability: A raw, log-based approach excels in writing large volumes of data reliably.
- Scalability: Kafka’s partitioned log structure supports horizontal scaling, enabling high message rates.
- Limitations:
- No Built-In “Latest Value on Demand”: Kafka doesn’t inherently push the latest value or any other changes to new subscribers. Clients must manage offsets and partitions themselves to retrieve the latest data.
- Client Complexity: “Smart clients” must implement features like constant polling or state tracking
- Advantages:
- Smart Brokers: These brokers also use a log-append foundation (writing data sequentially) but add extra features like topic-based routing, retained messages, and push-based distribution. This offloads logic from clients, potentially reducing CPU usage on low-power devices because the broker automatically pushes updates in real time.
- Advantages:
- Lower latency for real-time scenarios: as soon as the broker receives data, it sends it to subscribers without waiting for a poll.
- Less client overhead: devices don’t need to maintain code for fetching or caching the latest message.
- Advantages:
- Limitations:
- Risk of overload: a purely push-based model can flood a slow client if it can’t handle incoming data quickly (lack of built-in backpressure).
- Simpler routing vs. advanced routing: in MQTT, “dynamic routing” usually means wildcard topic matching, which is less flexible than something like AMQP’s routing exchanges
B.1.2 Summary of Architectural Comparisons
In manufacturing applications that run for decades, it is critical to have systems that can integrate new components or remove outdated ones with minimal reconfiguration. MQTT’s asynchronous design outperforms direct database polling or service calls for real-time telemetry. That’s one reason why MQTT thrives in so many IoT environments.
B.2 Comparing MQTT to Other IoT Protocols
We've established that MQTT's pub/sub approach is well suited for IoT. But is it unique? Let's compare it to other IoT protocols to see how it fares in the real world.
B.2.1 MQTT (Publish/Subscribe)
MQTT is a lightweight publish/subscribe protocol designed specifically for IoT applications.
It minimizes overhead—using a fixed header of only 2 bytes per publish packet—which makes it particularly suitable for low-power, resource-constrained devices. MQTT supports persistent sessions (with clean session = false), allowing brokers to cache messages for clients that are temporarily offline and ensuring that data is reliably delivered even in intermittent network conditions (theoretically, we’ll get to that in Chapter C). Once a TCP connection is established, MQTT can maintain it for long periods, enabling continuous, real-time message pushing.
However, MQTT’s reliance on TCP can introduce delays during connection setup or heavy network tuning. This is especially noticeable in satellite connections. In these specific cases, connectionless protocols such as CoAP, which operate over UDP, may have an initial latency advantage. There is also "MQTT over QUIC" (UDP-based), but that is not standardized yet and only available in EMQX.
However, for most IoT applications where a persistent connection is maintained, MQTT’s efficiency and robust delivery mechanisms make it the preferred choice for asynchronous data exchange.
Next, let’s look at AMQP, which originally comes from banking.
B.2.2 AMQP (Publish/Subscribe)
AMQP, the Advanced Message Queuing Protocol, was originally developed in 2003 for enterprise applications such as those at JP Morgan Chase. Although it was not designed specifically for IoT, AMQP is often compared to MQTT for its robust messaging capabilities in complex, enterprise environments. In its standardized form—AMQP 1.0—it supports a wide range of messaging patterns, including publish/subscribe, point-to-point, and even brokerless communication, along with features such as flexible routing and transaction guarantees.
It is important to note that many discussions of AMQP refer to version 0.9.1, which is what is implemented in RabbitMQ. This variant is not fully standardized, which can lead to interoperability challenges. In addition, AMQP has a higher overhead than MQTT due to its richer feature set and more complex message metadata, making it more resource-intensive.
Despite these differences, AMQP’s versatility and robust quality of service options make it a powerful tool for scenarios where complex routing and transaction integrity are required. As an example: as far as I understood, Azure's IoT Hub is based on AMQP.
Next, let’s look at CoAP, which differs greatly from AMQP because it operates over UDP and uses a REST-like approach.
B.2.3 CoAP (Service Calls)
CoAP (Constrained Application Protocol) is a lightweight protocol designed specifically for constrained devices and low-power networks. It operates over UDP and follows a RESTful, request/response paradigm rather than a native publish/subscribe model. This connectionless design minimizes overhead—with a typical fixed header of about 4 bytes—and can provide lower latency in environments where TCP connection establishment is problematic.
CoAP supports HTTP-like methods (e.g., GET, PUT, POST, DELETE), making it familiar for web applications while being optimized for resource-constrained contexts. It incorporates reliability through its use of confirmable (CON) messages, which require acknowledgments, and non-confirmable (NON) messages for less critical data, thereby balancing energy efficiency with the need for reliable delivery.
While CoAP is excellent for applications that require minimal power consumption and low latency, its RESTful request/response nature means that it does not inherently support continuous, asynchronous data streaming as efficiently as protocols such as MQTT.
B.2.4 MQTT vs AMQP vs CoAP
Several studies [3][4][5] have compared these protocols.
They generally conclude that MQTT provides an excellent balance of simplicity, low overhead, and reliable asynchronous communication for IoT telemetry, while AMQP delivers a richer feature set for complex enterprise messaging at the cost of higher resource consumption, and CoAP excels in energy efficiency and low latency in highly constrained environments, although its RESTful request/response model makes it less suitable for continuous, many-to-many data streaming.
The technical comparisons reveal that MQTT’s balance of simplicity, low overhead, and reliable asynchronous communication makes it ideally suited for IoT telemetry. But how does that look in practice?
B.2.5 Widespread Usage of MQTT
Several surveys, e.g., about developer preference, indicate that MQTT accounts for nearly 49% of the IoT market [6]. This widespread adoption reinforces the technical strengths discussed above and sets the stage for understanding its role in real-world deployments.
A survey by Mishra and Kertész (2020) [7] highlights several key trends:
- Exponential Growth in Research:
MQTT-related publications have grown at an average annual rate of over 30% from 2000 to 2019, reflecting increasing academic and industrial interest. - Dominance in M2M Communication Research:
Over the past five years, MQTT has led with approximately 14,600 publications compared to alternatives such as CoAP and AMQP, underscoring its importance in machine-to-machine communication. - Wide Applicability Across IoT Domains:
MQTT is used in a wide range of sectors—including healthcare, agriculture, logistics, disaster management, and smart city services—demonstrating its versatility in different application contexts. - Standardization and Industry Adoption:
With OASIS standardization in 2014 and ISO standardization in 2016, MQTT has become a cornerstone for reliable M2M and IoT systems. - Diverse Implementations and Ecosystem Support:
- MQTT Brokers: Approximately 50% of MQTT brokers are open source, indicating strong community involvement. But not all brokers implement the full set of MQTT features consistently; compatibility tests are recommended to ensure portability.
- MQTT Client Libraries: Approximately 83% of MQTT client libraries are open-source, providing developers with a wide range of options. Still, quality and completeness vary—some libraries (e.g., certain Go implementations) may have unresolved issues, while others such as Paho for Java and C remain the reference implementations.
- Multi-Language Support:
MQTT client libraries are available in multiple languages, including C, Java, and Python, which facilitates integration across different technology stacks.
Furthermore, an increasing number of industrial equipment manufacturers now offer native MQTT support. That said, MQTT integration isn’t always as seamless as OPC UA’s within the PLC vendors’ IDEs—often reflected by lengthy tutorials and manuals. We’ll revisit this issue in Chapter 3, where we’ll detail how PLCs are typically connected via MQTT—usually through the use of a protocol converter.
Examples include:
- Siemens: MQTT Client Documentation
- Rockwell Automation: MQTT Client Configuration
- Wago: MQTT Support
- Beckhoff: TwinCAT MQTT
B.2.5 Conclusion
While CoAP, AMQP, and other IoT protocols each have strengths, MQTT stands out for its minimal overhead and widespread adoption. Next, we’ll see if it can also hold its own against data-center-grade messaging systems.
B.3 Evaluating MQTT Against Data-Center-Grade Messaging Protocols
Industrial IoT often intersects with high-volume enterprise requirements. Although MQTT excels in constrained environments, what if you need advanced routing or massive throughput? Let’s compare MQTT to data-center-grade solutions like Kafka and RabbitMQ. However, these data-center-grade solutions serve different roles that can be understood through the “dumb versus smart broker” paradigm.
Platforms like Apache Kafka act as “dumb brokers.” Kafka operates as a log‐append system that persists messages without embedding sophisticated routing logic. This design shifts much of the complexity to the client side, which must handle polling, message ordering, and deduplication. Studies such as those by Dobbelaere and Sheykh Esmaili [8] and Hedi et al. [4:1] have demonstrated that Kafka can achieve throughput on the order of millions of messages per second under ideal conditions. However, Kafka’s reliance on disk-based persistence often results in higher latency than a smart broker like MQTT. This trade-off is most apparent in real-time scenarios. As a small side note: Kafka is currently moving more and more towards a smart broker as well, e.g., with its queue feature.
RabbitMQ, which implements AMQP (typically version 0.9.1 in many deployments), provides robust messaging features including flexible routing, transactional guarantees, and support for multiple messaging patterns such as publish/subscribe and point-to-point. Although RabbitMQ provides richer routing capabilities than MQTT, it has higher protocol overhead. For example, Lazidis et al. [9] report throughput numbers around 13,164 messages per second with latencies as low as 0.63 milliseconds in some configurations (compared to Kafka with (Kafka: 83,522 msg/sec vs RabbitMQ: 13,164 msg/sec and Kafka: 11msec vs RabbitMQ: 0.63msec ). It is worth noting, however, that interoperability challenges may arise with AMQP 0.9.1 since it is not fully standardized; the standardized AMQP 1.0 exists but is less commonly deployed.
NATS emphasizes simplicity and low operational overhead in cloud-native environments. While NATS is attractive for certain use cases, its more proprietary aspects and the need for vendor-specific solutions can limit its compatibility in heterogeneous enterprise environments.
It is important to recognize that these data-center-grade messaging systems are typically too complex or resource-intensive for direct deployment on edge devices such as sensors and PLCs, which are are better served by MQTT’s lightweight, topic-based model.
In many IoT pipelines, data is collected via MQTT at the edge and then bridged to data-center-grade systems such as Kafka for high-throughput processing and long-term storage.
In summary, although data-center-grade messaging platforms like Kafka and RabbitMQ are engineered for scenarios that require high throughput, durability, and advanced routing, MQTT’s decoupled, lightweight design remains optimal for real-time IoT telemetry. However, as we will explore in Chapter C, the very tradeoffs that make MQTT lean—minimizing overhead at the expense of sophisticated routing and processing features—may less ideal in manufacturing environments. In these contexts, where connections are stable and devices are less resource-constrained, a more feature-rich, enterprise-oriented messaging system may provide significant benefits.
B.4 Summary
MQTT’s lightweight, decoupled pub/sub approach makes it stand out for real-time IoT telemetry—especially where network or power constraints matter. Compared to other IoT protocols (CoAP, AMQP), MQTT strikes a balance between minimal overhead and reliable asynchronous communication. Although data-center-grade systems like Kafka or RabbitMQ offer richer features at scale, they can be overkill or too complex for constrained devices.
In Chapter C, we’ll see how this very tradeoff (minimal overhead vs. missing enterprise features) can become a limitation in manufacturing environments—and explore what to do about it.
Chapter C: MQTT Can Be Problematic in Certain Use Cases
In previous chapters, we focused on why MQTT is so popular—highlighting its minimal overhead, decoupled publish/subscribe architecture, and success in industrial IoT. However, MQTT isn’t a magic wand for all scenarios. While it excels in low-power or remote-edge environments, it reveals important trade-offs in enterprise-scale manufacturing networks—especially when transaction integrity, or guaranteed end-to-end delivery is critical.
This section explores:
- Why MQTT’s core advantage matters less in manufacturing
- MQTT Doesn’t Solve Everything — how MQTT’s QoS is mostly explained as a straight up lie, and that you need far more for typical manufacturing applications (e.g., data contracts)
- How hybrid approaches (e.g., protocol converters, bridging, or complementary systems like Kafka) can mitigate these challenges without losing MQTT’s lightweight advantages
C.1 MQTT’s Core Advantage (Low Overhead) Matters Less in Manufacturing
Many hail MQTT’s tiny fixed header—as small as two bytes—as its prime advantage. While that’s invaluable for battery-powered sensors or devices on flaky networks, it’s not always necessary in a manufacturing plant with robust Ethernet.
C.1.1 Edge and Remote Sensor Deployments
- Intermittent & Unstable Connectivity
Cellular or satellite connections can be flaky. MQTT’s persistent sessions and optional buffering reduce data loss during short disconnections. - Simplified Implementation
MQTT’s decoupled “publish anything, subscribe anywhere” eliminates heavier request–response logic on constrained devices. Perfect when minimal code is required on a microcontroller. - Extreme Resource Constraints
Battery-powered sensors or embedded devices typically have minimal CPU, RAM, and power availability. MQTT’s tiny fixed header (as small as 2 bytes) and lightweight publish/subscribe model reduce overhead and prolong battery life.
Teaser: Exactly this low overhead can cause problems in manufacturing environments!
Bottom Line (Edge)
MQTT’s overhead is so small that it’s a clear winner when you need to push data reliably from resource-constrained or intermittently connected devices.
C.1.2 Manufacturing and Industrial Environments
- Stable, High-Capacity Networks
Factories typically run wired Ethernet at 10 Mbit, 100 Mbit or gigabit speeds, where saving a few bytes of overhead is less of a priority. - Existing Protocol Ecosystem on the Shop Floor
Many PLCs speak Modbus, Siemens S7, or OPC UA —rewriting them to natively support MQTT is risky or time-consuming. Instead, plants often deploy a protocol converters gateway or “edge server” that polls legacy PLCs, converts data into MQTT topics, and publishes it upstream to a central broker (e.g., a Unified Namespace). This also simplifies bridging across a demilitarized zone (DMZ) (see figure further below). - MQTT's Low Overhead Diminishes with Long Topic Names
MQTT 3.1.1 is often praised for its minimal fixed header—just 2 bytes per PUBLISH packet. However, every PUBLISH packet in MQTT 3.1.1 also includes the full topic name as a UTF-8 encoded string in the variable header. When employing an ISA-95 hierarchical naming structure, these topic names can easily span 100–200 bytes, which considerably increases the overall message size. Although MQTT 5 introduces topic aliasing to mitigate this overhead by allowing clients to replace long topic names with shorter numerical aliases, many industrial systems still rely on MQTT 3.1.1. Consequently, in manufacturing environments where topic names are lengthy, the advantage of MQTT's low overhead is largely negated. - Simplicity for OT Engineers. Despite overhead not being critical here, MQTT remains simpler than heavier brokers like Kafka or AMQP. This simplicity is a major benefit for OT engineers who may not be comfortable configuring advanced enterprise platforms.
Bottom Line (Manufacturing)
MQTT is still beneficial for real-time event-driven architectures, but it sacrificed certain enterprise features (e.g., only-once delivery or transaction semantics) to achieve minimal overhead—features that matter more in stable, high-speed factory networks.
In stable factory networks, saving a few bytes is often not worth losing enterprise-grade reliability features.
C.1.3 Summary
While MQTT’s low overhead is unquestionably valuable for edge devices, it’s less critical in manufacturing contexts where bandwidth is ample, advanced messaging features can outweigh the benefits of extreme minimalism.
But MQTT’s main advantage is largely irrelevant for manufacturing, it also has serious drawbacks which we will explore in the next chapter.
C.2 MQTT Doesn’t Solve Everything (MQTT QoS Is a Lie)
MQTT’s built-in Quality of Service (QoS) levels often promise reliable delivery, but only on a single hop (client → broker). Once bridging, multi-broker topologies, or high throughput come into play, QoS alone doesn’t ensure end-to-end reliability. This is a major drawback in enterprise scenarios.
MQTT sits on top of TCP, which already retries lost packets, yet MQTT adds another layer of acknowledgments—QoS. So why do large manufacturing environments still experience data loss? Mainly because of QoS limitations.
1. QoS 0 (“At Most Once”)
- Minimal Overhead: The message is sent without acknowledgment.
- Risk of Loss: If the broker or client is offline, data simply vanishes.
- Ideal For: Frequent sensor readings where occasional drops are tolerable.
QoS 1 (“At Least Once”)
- Guaranteed Delivery—But Possibly Duplicated: Messages won’t be silently lost but may arrive multiple times.
- Higher Overhead: You must handle duplicates at the application layer (i.e., implement idempotence).
QoS 2 (“Exactly Once”)
- Four-Step Handshake: PUBLISH → PUBREC → PUBREL → PUBCOMP.
- Single-Hop Only: “Exactly once” applies only between this client and broker. It doesn’t guarantee delivery from the publisher to the consumer (we’ll get into that soon!). In some brokers like HiveMQ and when using shared subscriptions QoS 2 is automatically downgraded to QoS 1.
- Rarely Used: The overhead is significant; most large-scale systems prefer QoS 1 plus their own deduplication.
C.2.1 The Two‑Generals Problem
The Two-Generals Problem is a classic thought experiment illustrating that no amount of acknowledgments can guarantee two parties each know that the other knows, if messages (or ACKs) might be lost:
- Scenario: Two generals exchange messengers across enemy territory. The final messenger could be intercepted, so each side is unsure the other actually got the plan and final ACK.
- Conclusion: It’s theoretically impossible to achieve 100% certainty on an unreliable link with acknowledgments alone.
MQTT and QoS 2 attempts to resolve “exactly once” on a single hop (via PUBLISH → PUBREC → PUBREL → PUBCOMP), but bridging or multi-hop setups reintroduce the same fundamental uncertainty at every stage.
C.2.2 Multi-Hop Bridging
For example, you might have an edge-level broker running on a local device (collecting PLC or sensor data), which bridges to a “line broker” in the same factory cell, which in turn bridges to a site-wide or enterprise broker behind a DMZ. Each broker acts as both a subscriber and publisher for specific topics, enabling data to flow securely across segmented networks.
This layered approach helps address security and scalability concerns—like isolating critical systems behind DMZs or buffering data at the edge for quick local response—even though it introduces extra hops where messages can be requeued, delayed, or partially replayed if not carefully configured.
See also our website for more information.

In multi-broker bridging, each hop is effectively a new client–broker link. Even if each uses QoS 2 locally, there’s no global handshake. You can end up with out-of-order duplicates or partial replays. Consequently, bridging often reverts you to “at least once.”
C.2.3 Multi-Step Processing
Many industrial environments use DataOps or stream-processing tools to refine data at multiple stages. For example, a DataOps application may subscribe to the broker’s raw sensor topics, clean or normalize the data, and then republish it under new topics. Later steps might include modeling—calculating KPIs or contextualizing data in an ISA-95 hierarchy—and eventually, threshold-based alerting.
Technically, this means multiple “hops” in the data flow: each DataOps stage subscribes to an incoming topic and publishes a transformed message back to the broker. As with multi-broker bridging, MQTT QoS only protects each individual hop rather than guaranteeing complete end-to-end reliability. The more hops you have, the more likely a failure—or even minor delays—will disrupt your data.
A prime example is threshold-based alerting. Even if you assume MQTT QoS ensures at-least-once delivery (QoS 1), your alert logic still has to handle duplicates or late-arriving messages. Suppose sensor spikes arrive minutes after the actual event; by then, your system may have shown “healthy” readings, masking the original anomaly. Or if the spike readings trickle in slowly over multiple intervals, the DataOps tool’s “if value > X, then alert” rule may never see the full spike in a single message, resulting in no alert triggered at all.
Next, we’ll explore another built-in constraint of MQTT that can further complicate reliability at scale: the 2-byte Packet Identifier limit.
C.2.4 2‑Byte Packet Identifier Limit (~65 k)
Even if you ignore the Two‑Generals angle, MQTT QoS 1/2 relies on a 2‑byte Packet Identifier. This theoretically caps you at 65,535 in-flight QoS 1/2 messages per client–broker connection. (“In-flight” = messages that have been sent but not yet fully acknowledged.)
However, real brokers typically impose much lower in-flight or storage limits per client (e.g., 1,000). These forced drops or blocking events occur well before 65k is reached.
C.2.5 Forced Drops or Blocking
Using HiveMQ as a good and well-documented MQTT broker—but applying to all major brokers:
1. Slow Subscribers
When a subscriber (or bridging gateway) consumes messages too slowly, the backlog of undelivered messages grows. Brokers often handle this by discarding unacknowledged QoS 0 messages first (to avoid ballooning memory usage). If the backlog persists, brokers may even block or disconnect QoS 1/2 clients, regardless of whether QoS is set to "at least" or "exactly" once.
Example: HiveMQ’s Overload Protection [10]
2. Queue & Memory Limits
Brokers define a per-client queue size (e.g., 1,000 messages) and an overall memory limit. Once these are reached, fresh QoS 0 messages are dropped. QoS 1/2 messages are “stalled” in an unacknowledged state—potentially leading to blocked connections if the backlog isn’t cleared.
Example: HiveMQ’s max-queue-size [12]
C.2.6 Summary
MQTT QoS helps reduce silent data loss on a single hop, but it can’t ensure truly end-to-end reliability once you have bridging, multi-step processing, or significant broker limits. Threshold-based alerting and other real-time analytics often fail under delayed or duplicate data. If MQTT cannot solve all of our problems, then what then? We need something else on top of it.
C.3 Something Else On Top: A hybrid approach with MQTT + Data-Center-Grade Brokers + Data Contracts
If MQTT alone doesn’t cover advanced reliability needs or bridging complexities, you can complement it with heavier brokers (AMQP, Kafka) and an application-level data contract. This synergy keeps MQTT’s simplicity at the edge while ensuring robust, replayable, and transaction-friendly messaging in the backend.
C.3.1 AMQP/Kafka Solve QoS “Better”
While MQTT focuses on minimal overhead, AMQP and Kafka include richer reliability features:
- AMQP: Supports transactional acknowledgments, flexible routing, exactly-once semantics in principle.
- Kafka: Log-based, disk-backed approach with partition-based scaling and replay. If your consumer is offline for hours, it can catch up from the log once it reconnects—no forced drops as long as data remains in Kafka’s retention window.
- Compared to MQTT, Kafka basically never “forgets” a message unless it has expired in the retention window, so QoS in Kafka is simpler from a “no data loss” perspective.
But these data-center-grade brokers come with more overhead and complexity. MQTT remains simpler for OT. The challenge is to bridge the gap without forcing OT engineers to adopt a massive enterprise platform on the shop floor.
Hence a hybrid system: Collect data via MQTT at the edge (easy for PLCs) → push or bridge that data into Kafka or AMQP for long-term reliability, replay, or advanced routing.
But coupling MQTT with other data-center-grade brokers doesn’t magically solve all your problems. We need something more.
C.3.2 Something More: Data Contracts (Application Protocols)
So far, we’ve seen that MQTT (even combined with QoS) only provides transport—the lower layers of the OSI model.
If you need application layer guarantees—like “exactly once” or safe command execution without duplicates—you need to add a higher-level protocol. In modern industrial IoT systems, we call this a data contract.
C.3.2.1 Data Contracts in Theory
Data contracts address the question of how two applications actually interpret the data being exchanged—beyond simply receiving bits over MQTT or another transport. Some experts, such as Matthew Parris, outline a multi-layer Data Access Model, where “transport” (e.g., MQTT, OPC UA, AMQP, Kafka) lies below an “information” or objects layer. At that higher layer, the structure and semantics of data—things like field names, data types, or machine states—must be consistently defined across systems. ‘Consistently defined’ doesn’t mean your schema can never change—it means that any changes must adhere to predefined rules to ensure consistency across systems.
That is precisely where data contracts come in. Subscribe to our newsletter if you want to be informed when our podcast drops together with Matthew Parris, where we talk about this in detail.
A data contract is an agreement that specifies what fields are exchanged, in which format, and under what assumptions. It ensures that each consumer, regardless of transport mechanism, can parse and process messages correctly. Concretely, a data contract typically covers:
- Object Schema: Which attributes exist (e.g.,
temperature,status,timestamp_ms) and their data types. - Versioning Rules: How to handle changes (e.g., new fields or renamed fields) so that consumers can evolve without breaking.
- Idempotence & Ordering: Logic for handling duplicate or out-of-order messages.
- Validation & Semantics: Requirements for valid values, time windows, or metadata—so recipients can trust the payload they receive.
- Application-Level Handshakes: To ensure true end-to-end reliability, the data contract can include additional handshake mechanisms at the application layer. For example, after processing each message, the receiver may send a confirmation response verifying that the message was successfully handled (see our example for
_actionmessages below).
One example of a data contract is Sparkplug, which sits on top of MQTT to define a consistent naming structure, data types, and publish/subscribe behavior. Sparkplug effectively standardizes the “objects layer,” giving different devices or applications a shared language for how to name tags and how to interpret payload changes. While Sparkplug addresses some of the interoperability gaps, we think it falls apart when used in manufacturing.
We will cover data contracts in a future article. If you can’t wait, you can check out the podcast that I did with David Schultz
For a deeper historical perspective on idempotence, see Pat Helland’s “Idempotence Is Not a Medical Condition.”[11]
C.3.2.2 Example: _historian for Idempotent Storage
In the UMH approach, _historian is a ready-to-use data contract that ensures time-series data—“tags,” e.g. temperature or PLC registers—enters the database once and only once.
- Topic & Payload Rules
- You publish your data to a topic path like
umh/v1/enterprise/site/area/.../_historian/optional_tag_groups/...
- You publish your data to a topic path like
- Idempotent Writes
- Each
(enterprise, site, area, …, timestamp_ms, tag)is unique in the database. If the same record arrives again,_historiandeduplicates it automatically. - This leverages the “at least once” semantics of MQTT or Kafka while preventing double inserts.
- Each
Payload must have timestamp_ms and at least one named key for the measurement:
{
"timestamp_ms": 1732280023697,
"my_sensor": 42.5
}
Result: You can safely replay or resend data without polluting the historian table. If you want more details on _historian configuration, check our Historian Data Contract docs.
C.3.2.3 Example: _action for Safely Writing to a PLC
While _historian is for one-way data (notification), you may need a request/response pattern for writing commands—like telling the PLC “update order_id to 12345.” That’s what an _action data contract might look like:
{
"command_uuid": "fc3fede5-125d-4567-aabc-def56789012",
"action": "WRITE_ORDER_ID",
"parameters": {
"order_id": 12345
},
"timestamp_not_before": 1694457612345,
"timestamp_not_after": 1694457712345
}
- Idempotent
command_uuidprevents repeated commands if the broker resends. The receiver (e.g., protocol converter to PLC) checks if it’s already processed “fc3fede5…”
- Time Windows
timestamp_not_before/timestamp_not_afterensure commands older than 30 s (for example) are discarded if they got stuck in a backlog.
Note:_actionis not built-in by default in UMH, but you can add a custom data contract with bridging for_action/*. Then your “PLC gateway” protocol converter only executes the command if it’s new and valid.
C.3.2.4 Bottom Line
A data contract is your application-level agreement that ensures consistent data schemas, deduplication, and safe command execution—beyond raw MQTT. By defining schemas like _historian or _action, you eliminate risk of partial duplicates and unify your edge (MQTT) with robust enterprise logic (Kafka or local DB). For more advanced setups, see the UMH data contracts reference or the next sections on hybrid architectures.
C.3.3 UMH’s Hybrid Architecture
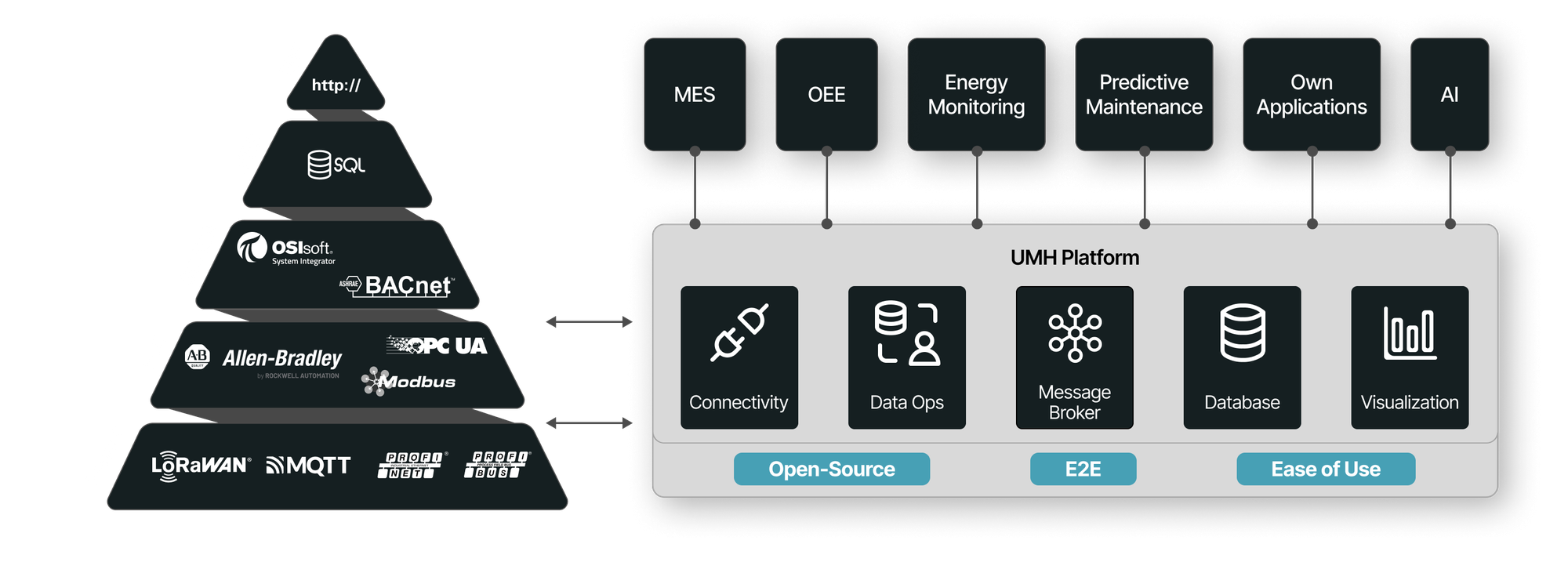
UMH implements exactly this hybrid approach. At the edge, MQTT subscribers process events from PLCs, sensors, or microcontrollers—delivering them upstream with little overhead. Meanwhile, UMH uses Kafka to log all messages in an append-only fashion, ensuring zero data loss and enabling advanced analysis or replay. The bridging process, powered by Benthos-UMH, translates device data into standardized JSON messages, organizes them in an ISA-95-based hierarchy, and forwards them to Kafka for stable retention. On the enterprise side, data consumers can use this guaranteed stream for everything from real-time monitoring to big-data analysis, confident no messages are silently lost or duplicated.
To tie it all together, data contracts (application-level logic) run on top of MQTT/Kafka, clarifying exactly how messages are structured and ensuring idempotent writes or commands. This synergy addresses each shortcoming we identified: you keep MQTT’s simplicity for shop-floor devices, Kafka’s strong reliability for back-end services, and a clean contract-based model so critical commands aren’t unexpectedly replayed. In short, a hybrid edge–data-center-grade solution results in a truly end-to-end system, that gives OT engineers the agile, event-driven workflows they crave, while providing IT teams with the guaranteed, scalable data backbone needed for advanced operations.
Remember our threshold-based alert example from before? With Kafka’s replayable log and a data contract enforcing event ordering, an alerting engine can now easily handle late, out-of-order data without missing anomalies.
C.4 Conclusion
A hybrid approach delivers a true end-to-end system: agile, event-driven workflows on the shop floor, plus guaranteed reliability and advanced features in enterprise data pipelines. Instead of relying on MQTT's QoS to solve all reliability challenges, MQTT combined with an data-center-grade broker and data contracts fills the gaps that matter in manufacturing—giving you the best of both worlds.
Summary
Remember how we started this article by saying that most MQTT explanations suck? Now you see why-they lack honest coverage of QoS illusions, bridge complexity, and ignore the larger IoT landscape.
Most MQTT explanations suck because:
- They fixate on advanced QoS or niche features, burying newcomers in details without explaining the broader MQTT architecture.
- Conflate "publish-subscribe" with MQTT exclusivity, omitting that AMQP or other protocols can provide the same pattern with additional enterprise features.
- They fail to contextualize MQTT for manufacturing, neglecting that minimal overhead may not outweigh missing capabilities (e.g., transactions, replays) in robust factory networks.
- They misrepresent QoS-treating it as a total solution while glossing over the complexities of multi-hop bridging and ignoring that QoS 2 often breaks down at scale.
- They skip over the need for an application-level protocol (data contracts) for true end-to-end reliability-leaving new users unprepared for bridging or multi-broker setups.
MQTT alone isn't the end-all, be-all for Industrial IoT - especially in stable factory environments that require advanced reliability. However, MQTT is unbeatable for ultra-lightweight IoT telemetry, so the real answer is a hybrid approach. Combine MQTT for your edge devices, Kafka/AMQP for data-center-grade robustness, and data contracts to unify them. Tools like the UMH make this synergy seamless, combining OT-friendly simplicity with IT-grade reliability.
Don't fall for the illusion that "MQTT/UNS fixes everything. Leverage a robust, hybrid architecture-so your manufacturing data flows from sensor to cloud without half-baked or mismatched solutions. That way, you'll get the real power of MQTT without the hidden pitfalls.
Acknowledgements
A big thank you to the following people, who gave me valuable feedback when creating this article:
- Alex Kritikos (technical committee member of MQTT and AMQP)
- Andreas Vogler (creator of MonsterMQ)
- Davy Demeyer (Founder of Acceleer)
- Kristof Martens (Partner at Dataminded)
- Matthew Parris (Senior Manager, Advanced Manufacturing – Test Systems, GE Appliances)
- Ricardo Maestas (IT/OT system integrator)
- Eugster, Patrick Th., et al. “The Many Faces of Publish/Subscribe.” ACM Computing Surveys, vol. 35, no. 2, 2003, pp. 114–131. ↩︎
- Kleppmann, Martin. Designing Data-Intensive Applications. O'Reilly Media, 2017. ↩︎
- Al Enany, Marwa O., et al. "A Comparative Analysis of MQTT and IoT Application Protocols." 2021 International Conference on Electronic Engineering (ICEEM), 2021. ↩︎
- Hedi, I., Špeh, I., & Šarabok, A. "IoT Network Protocols Comparison for the Purpose of IoT Constrained Networks." MIPRO 2017, 2017. ↩︎ ↩︎
- Jeddou, Sidna, et al. "Analysis and Evaluation of Communication Protocols for IoT Applications." 13th International Conference on Intelligent Systems: Theories and Applications, 2020. ↩︎
- https://outreach.eclipse.foundation/iot-edge-developer-survey-2023 ↩︎
- Mishra, Biswajeeban and Attila Kertész. “The Use of MQTT in M2M and IoT Systems: A Survey.” IEEE Access 8 (2020): 201071-201086. ↩︎
- Dobbelaere, P., & Sheykh Esmaili, K. "Kafka versus RabbitMQ: A Comparative Study of Two Industry Reference Publish/Subscribe Implementations." In Proceedings of the 11th ACM International Conference on Distributed and Event-based Systems, 2017, pp. 227–238. ↩︎
- Lazidis, A., Tsakos, K., & Petrakis, E.G.M. "Publish-Subscribe Approaches for the IoT and the Cloud: Functional and Performance Evaluation of Open-Source Systems." Internet of Things, 2022. ↩︎
- HiveMQ Documentation: Overload Protection. https://www.hivemq.com/docs/hivemq/latest/user-guide/overload-protection.html ↩︎
- Helland, Pat. "Idempotence Is Not a Medical Condition." Communications of the ACM, 2012. ↩︎
- HiveMQ Tuning Guide: https://www.hivemq.com/docs/hivemq/latest/monitoring-and-tuning/tuning-guide.html


