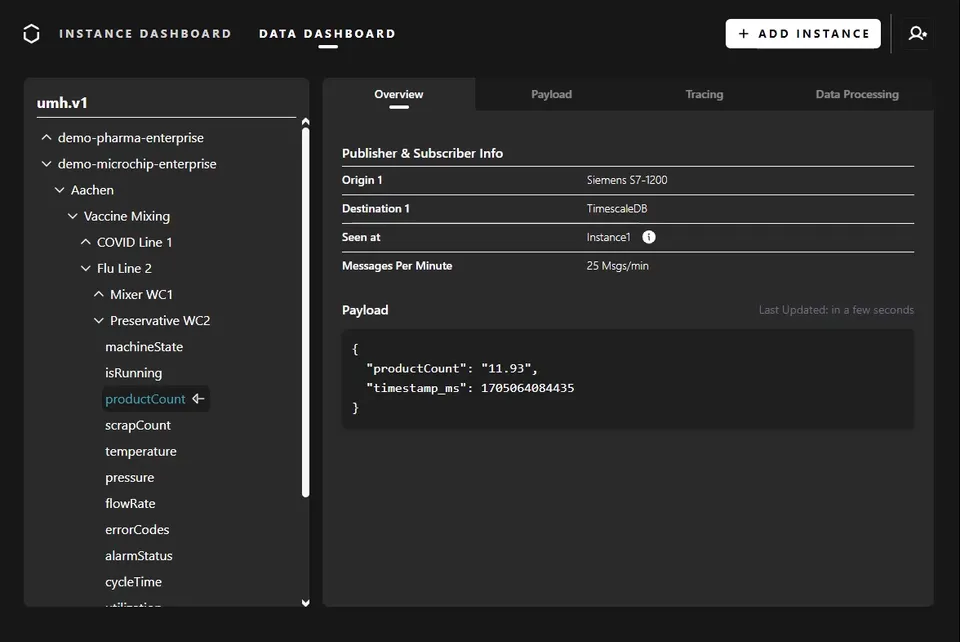
At the heart of this emerging concept stands Walker Reynolds, an educator/influencer who offers a unique OT/system-level perspective on the Unified Namespace (UNS).
Definition of the UNS
Walker describes the Unified Namespace (in short: UNS) as a framework where all applications and devices in Industrial IoT act as interconnected nodes, sharing and accessing data in a single unified location.
To be honest, that is quite a vague definition. So let’s clear it up! There are additional key components that people typically talk about when talking about Unified Namespace:
Component 1: Event-Driven Architecture
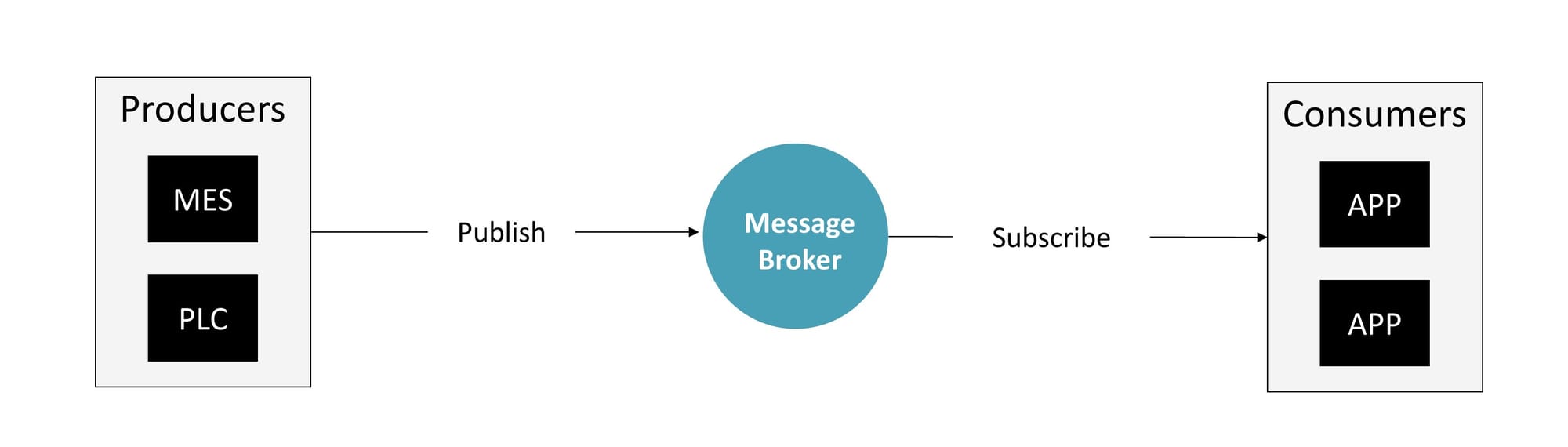
The foundation of a UNS is an Event-Driven Architecture, which facilitates real-time message exchange between multiple entities, referred to as consumers and producers. Central to this architecture is the use of a message broker. In the UNS, almost always people talk about MQTT as the central message broker protocol. There are some commercial vendors out there, which we compared here. In Chapter 3 of this article, we will go through the origins of UNS and go a little bit more into detail of alternatives to Event Driven Architecture here.
Component 2: Standardized Topic Hierarchy
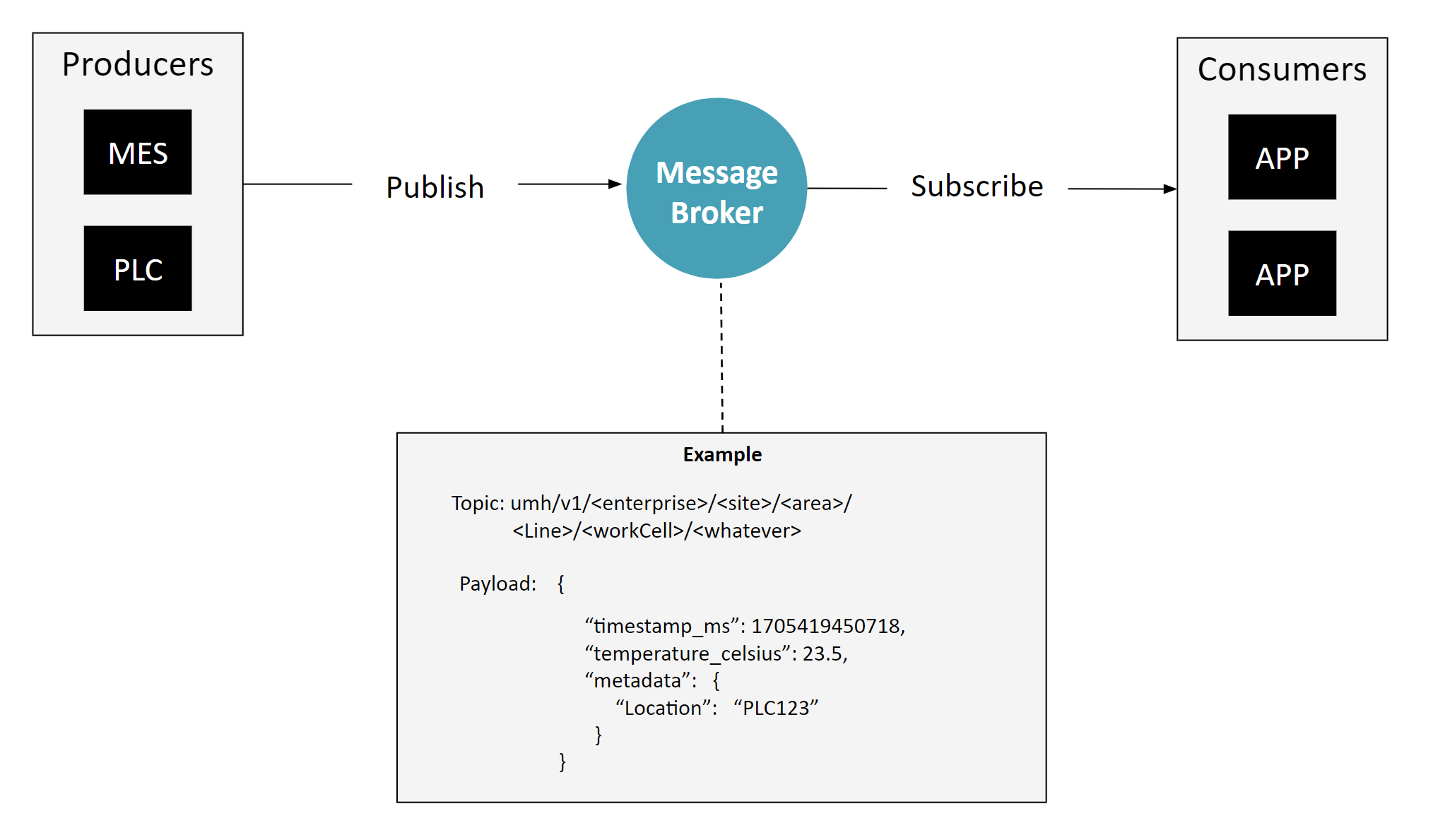
Additionally, the system employs a standardized topic hierarchy accompanied by a defined message schema. This typically follows an ISA95-style framework for topic organization (encompassing enterprise, site, area, line, and cell levels). While this hierarchy is generally consistent, adaptations are common across different industries - for instance, energy companies might use the KKS System, and pharmaceuticals often adopt ISA88 principles. Furthermore, assets might be classified numerically, and lines and cells can be merged, among other variations. The message schema becomes crucial when scaling, as it ensures adherence to the topic hierarchy and standardizes the messages within it.
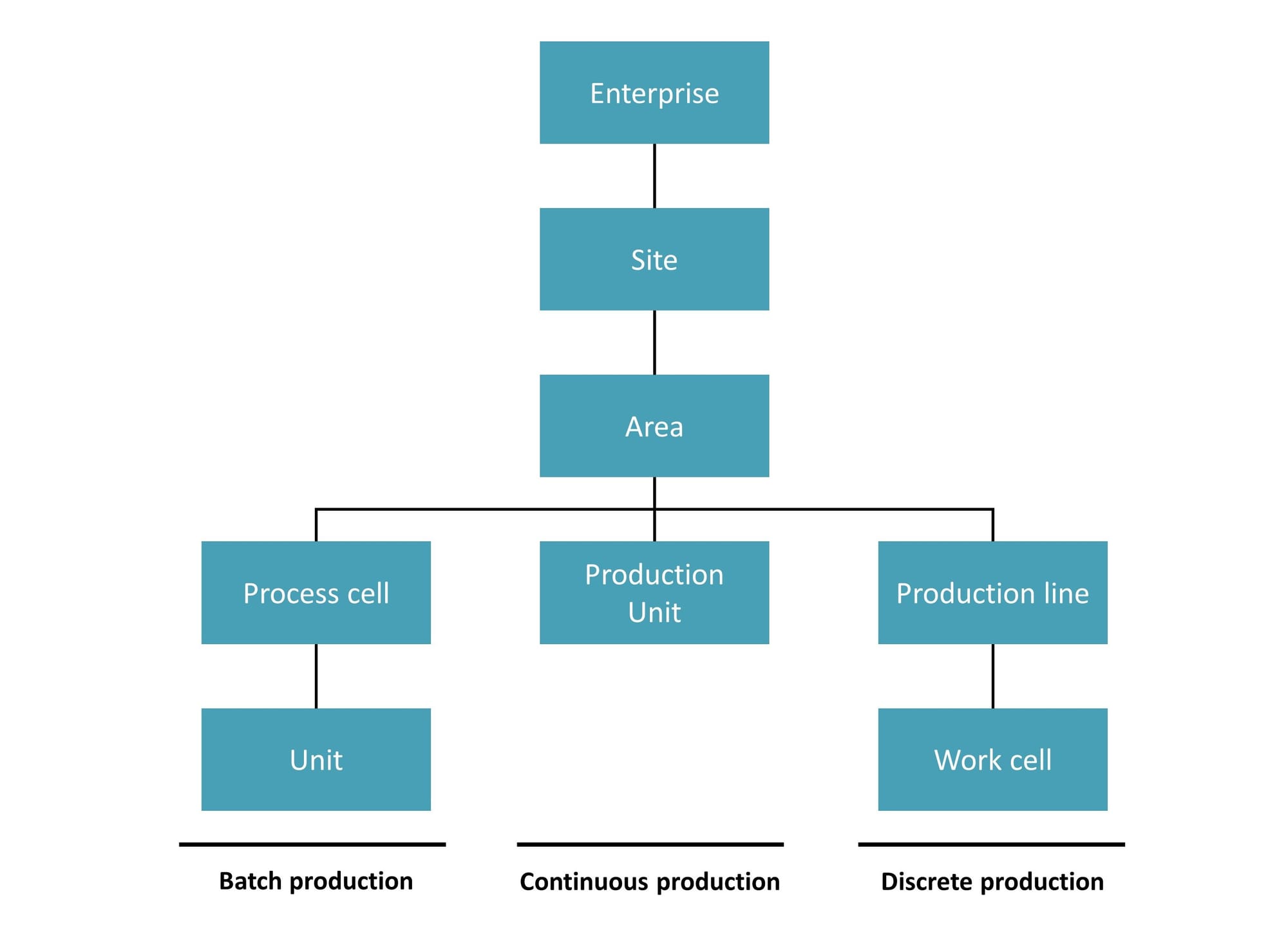
Take a look into the final words chapter for more information on designing the topic hierarchy.
Component 3: Messages are sent to the message broker regardless of the immediate presence of a consumer.
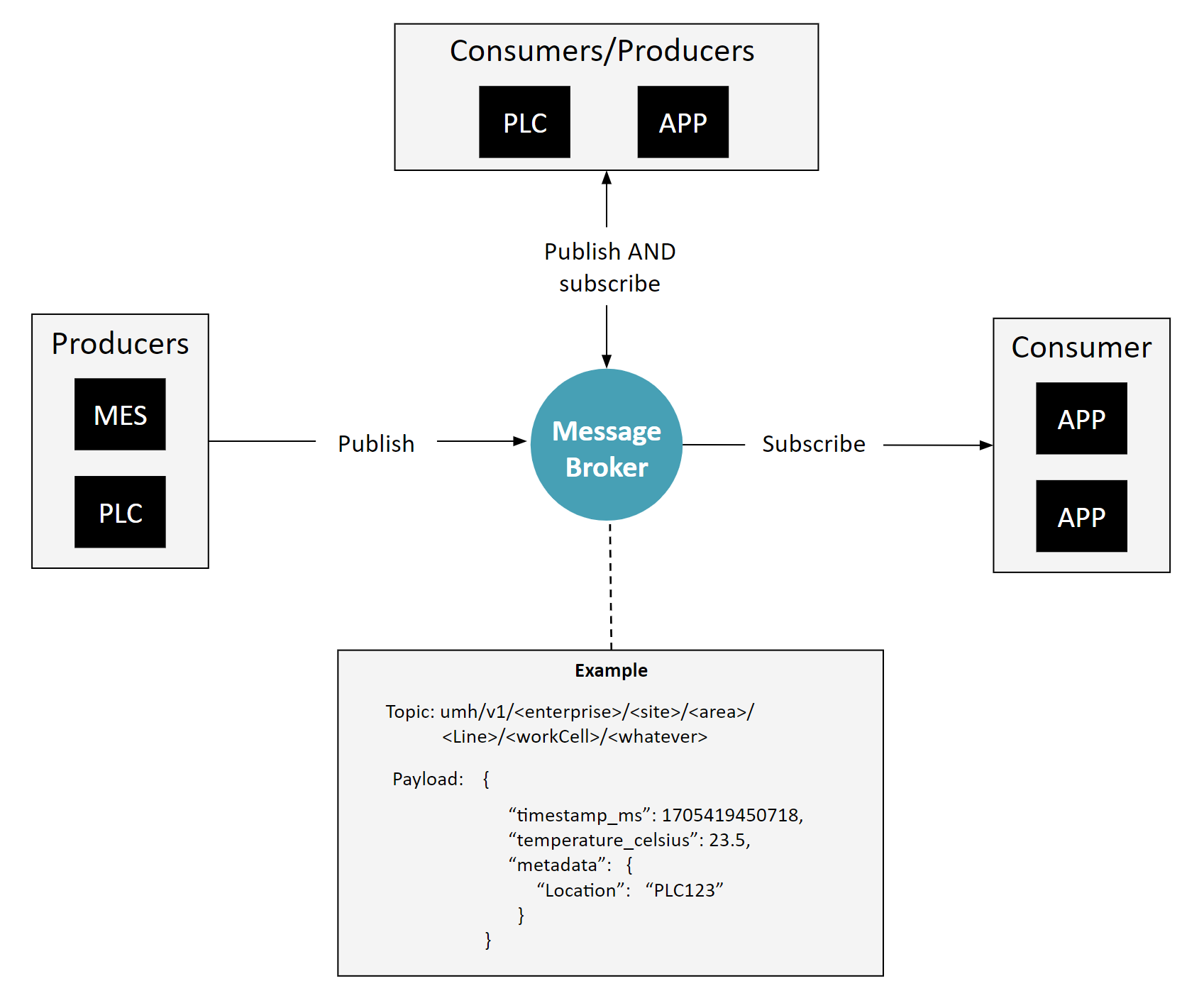
This strategy diverges from conventional IT practices, where the production of data for a message broker or an event-driven architecture usually hinges on the existence of a consumer.
Our initial thoughts, formulated before the concept of the Unified Namespace gained widespread recognition, centers on the fact that establishing connections and extracting data on the shop floor is a time-consuming process. Therefore, our initial step involves sending all accessible data during the configuration of the producer or the protocol converter into the message broker. Once this data reaches the message broker, we can more easily determine which data points to retain, whether down sampling is necessary, and so forth. It's likely that many professionals working with Unified Namespace employ a similar approach, often instinctively, without much discussion.
This method is feasible because the volume of data from OT systems is generally minimal compared to the capacity of contemporary IT applications. Consequently, these applications are typically indifferent to whether they receive a few hundred data points per second or as many as 30,000.
Part of this approach also entails that any application which extracts data must also contribute its processed data back into the system. This results in significant time-saving when expanding existing use-cases. Because all the data is already there, available in a simple, standardized and easy to access format, adding a couple of data points to the dashboard, or setting up an AI model, becomes a thing of a couple hours.
Some refer to this as "democratizing data", which you might know when you work at a larger enterprise and struggle to sometimes get very few data points.
Component 4: Stream Processing / Data Contextualization
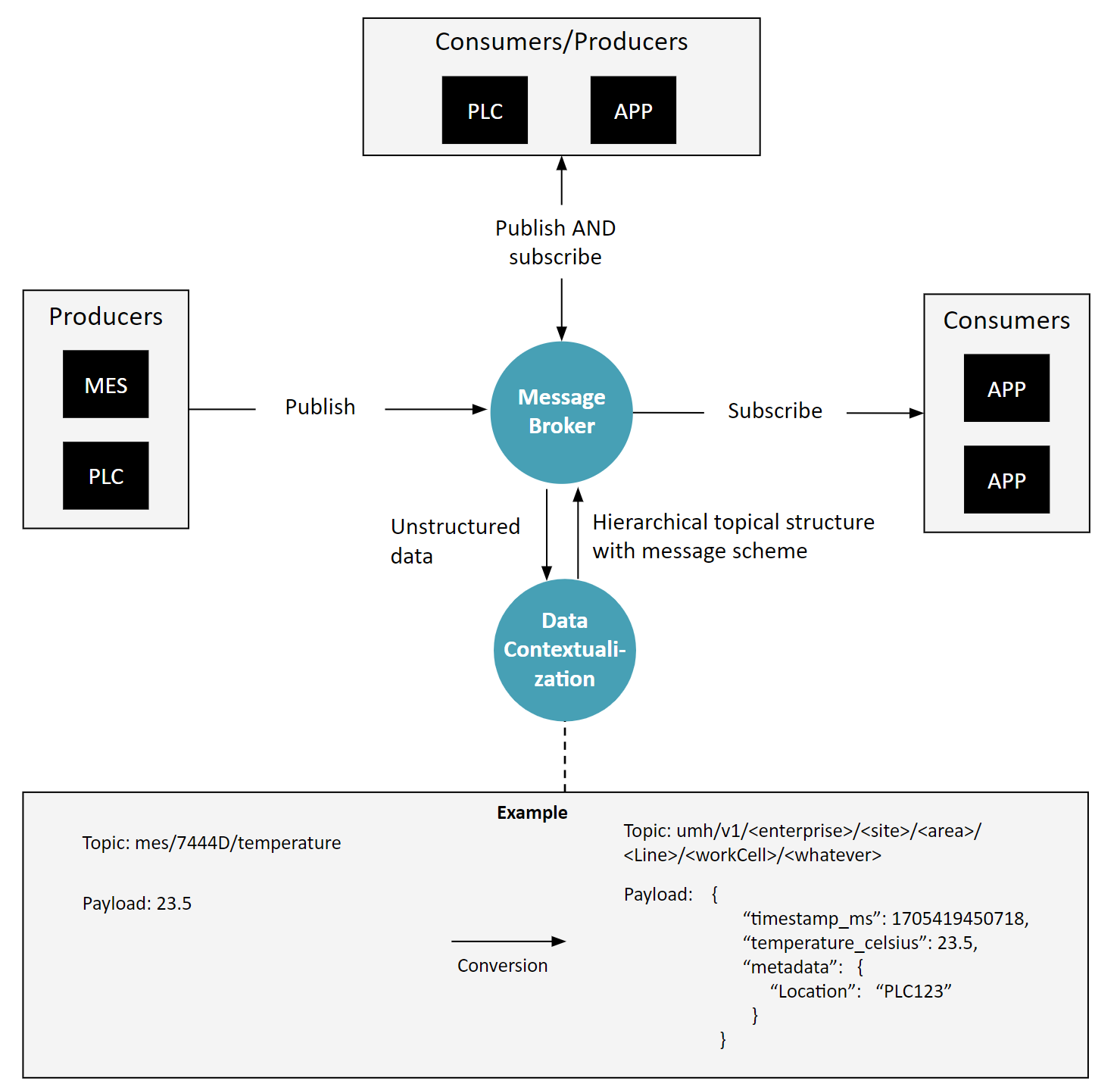
So far, our discussion on technology has been centered mainly around a message broker and certain rules (like topic hierarchy, schema, and what to publish). However, there is another key technological component crucial to a Unified Namespace, which we refer to as Stream Processing or Data Contextualization. These steps can be done either in smaller tools or inside of an larger IIoT platform.
The core function of this component is to properly place data into the Unified Namespace. This means ensuring data fits into the correct topic hierarchy and conforms to established message schemas.
For example, consider a message 23.5 coming in on a topic mes/7444D/temperature. One could now assume that it is a temperature in celsius coming from the MES from a device called 7444D. This component might take this raw data, identify it as a temperature reading, and then place it under a specific topic like umh.v1.united-manufacturing-hub.cologne.weather together with a more standardized payload containing a timestamp and metadata within the Unified Namespace.
Tasks can range from this simple, like redirecting a message to a different topic, to more complex, such as breaking down a large message into multiple smaller events across various topics. Additionally, it can involve sophisticated algorithms for data processing. For instance, it might implement a rule that triggers an action if a machine’s vibration exceeds 30, indicating potential issues in operation.
Common tools used in this process include Node-RED, Ignition, and HighByte.
Component 5: Protocol Converters
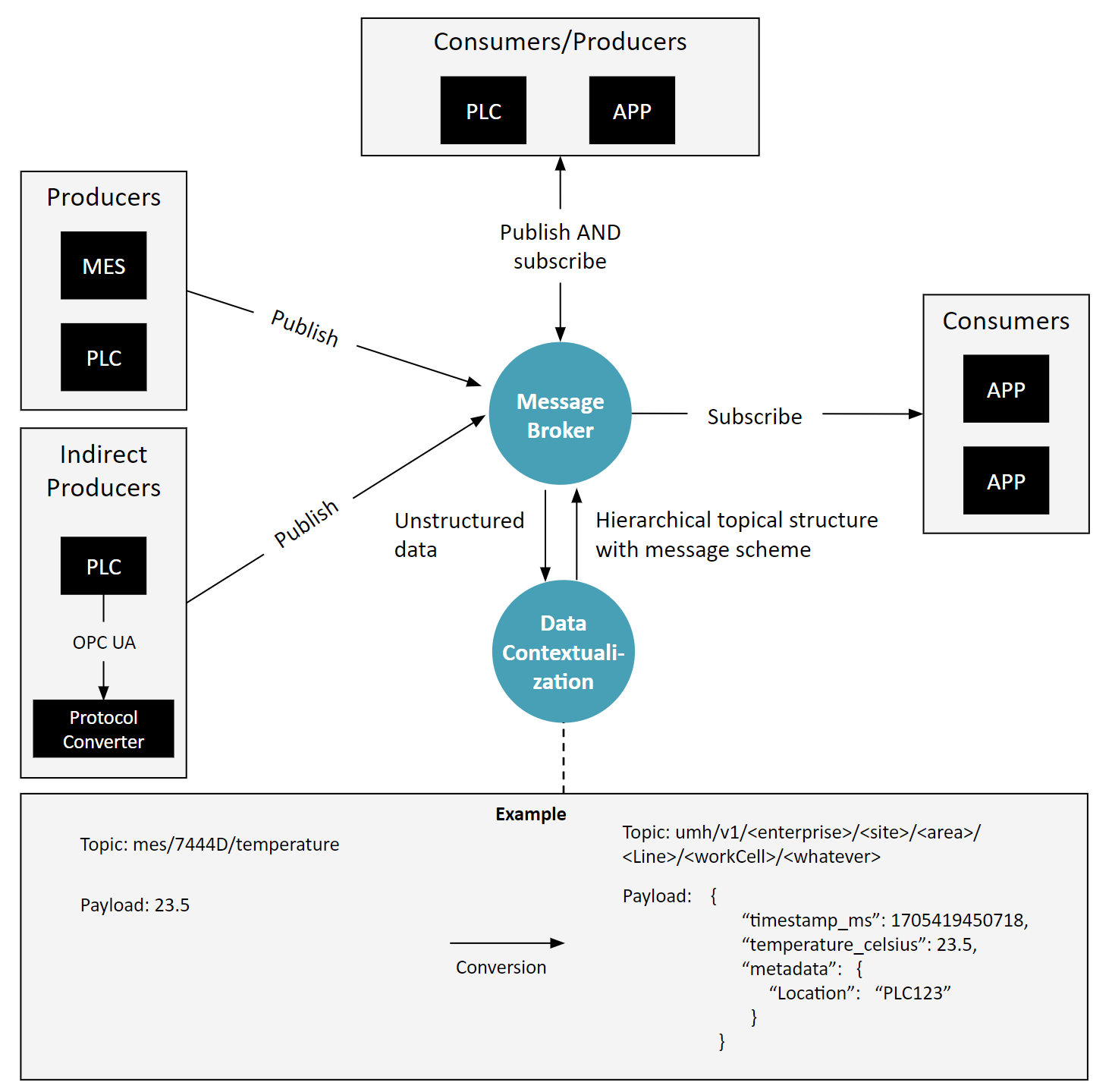
Optionally, there are also “protocol converters” in cases necessary, where the consumers might not speak MQTT, but OPC UA or SQL or something else, so the data first needs to be converted from these protocols into the event-based messages.
This sounds easy at first, but the reality is way more complex. Especially, when the origin of the data is not something event-based, but instead something like a database. In the chapter "final words" you will find more reading material on this topic.
The result: Open and Replaceable Architecture
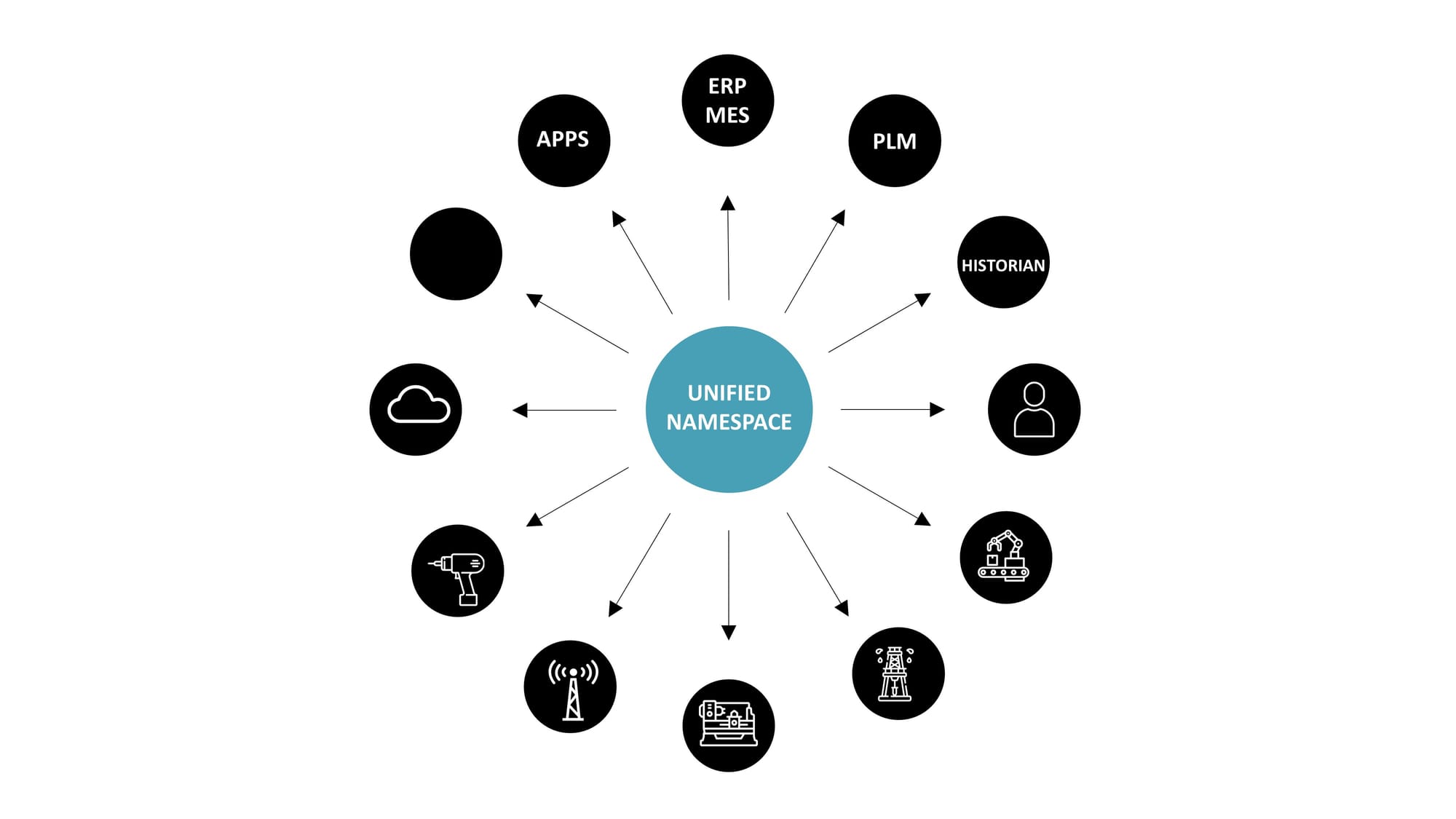
Firstly, it represents a truly open architecture. The term "open architecture" has often been misused by many large-scale OT vendors, who have branded their proprietary, restrictive architectures (or protocols, like OPC UA) as "open." This is misleading because if we define "open" as "allowing every application or person easy access to data," it implies that the underlying interfaces should be simple, well-documented, non-proprietary, and supported by multiple major vendors from various ecosystems. While OPC UA is extensively documented, it is far from simple. A system that needs hundreds of lines of code just for data extraction is not user-friendly. It's essentially limited to large vendors who can afford to invest in comprehensive SDKs.
Moreover, the Unified Namespace is a vendor-independent, replaceable architecture. This aspect challenges established market vendors as it enables the replacement of any software component with minimal vendor lock-in, in line with UNS guidelines. Even key components like the message broker are interchangeable, as seen in the variety of available MQTT brokers. For instance, a salesperson promising exceptional results can be granted access to the company's data through the UNS to demonstrate the value of their application within hours. Similarly, if a vendor fails to meet expectations, they can be readily replaced with another. This flexibility and independence from single vendors is a crucial feature of this architecture.
To illustrate these concepts more clearly, let’s use an easy-to-understand metaphor.
The Unified Namespace as a 1980s News Agency
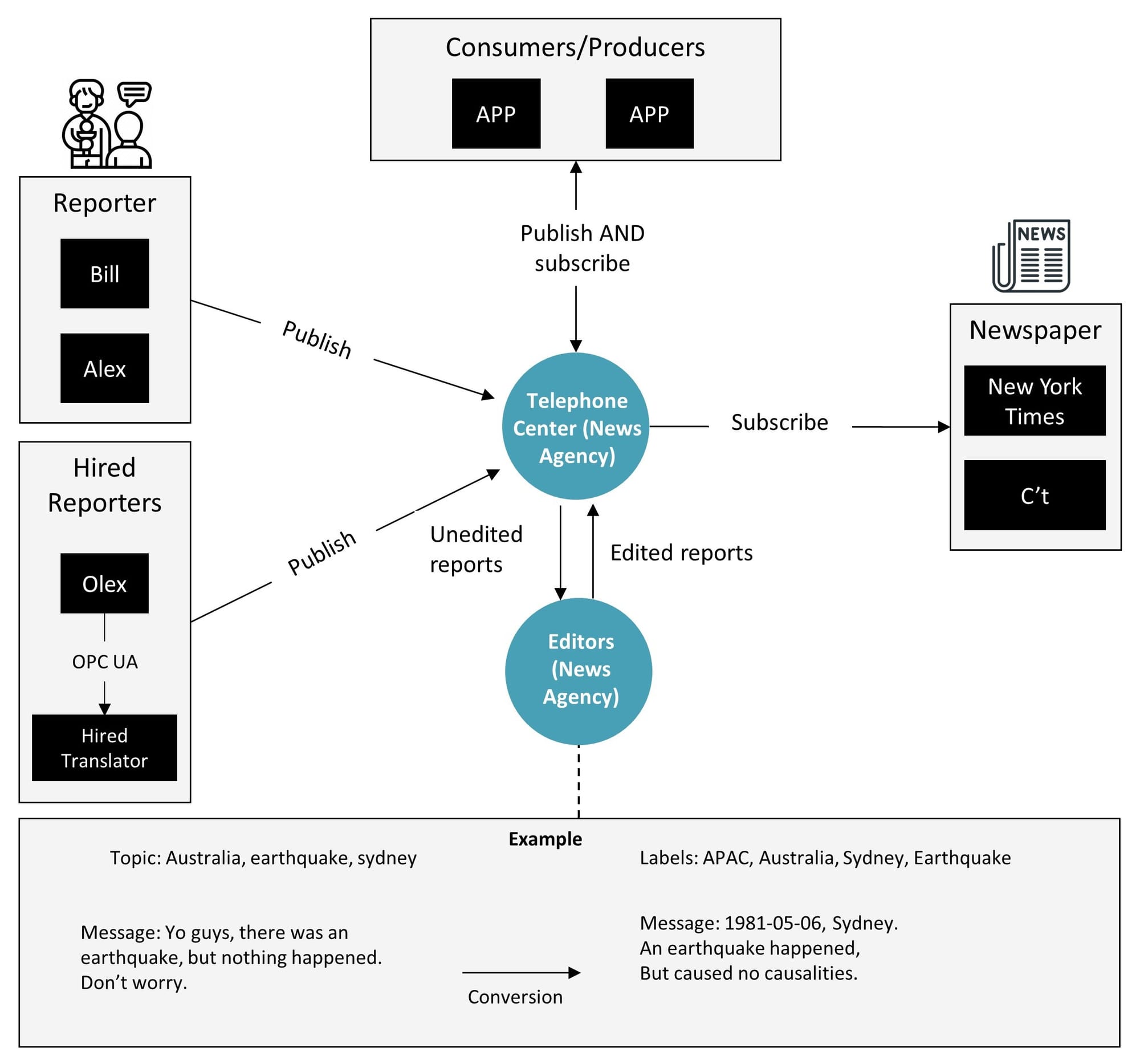
Imagine the Unified Namespace as a bustling news agency from the 1980s. In this agency:
- Reporter and Messages (Data Producers and Events): Each data source in the Industrial IoT is like a reporter. Just as a reporter sends news about events to the news agency, like an earthquake in Sydney, these data sources generate messages about events in the factory and sends them to the message broker. They label these messages with specific tags, such as "earthquake", "Australia", "Sydney", mirroring how data is tagged with a topic hierarchy in the UNS.
- Telephone Center (Message Broker): The news agency’s telephone center, where all messages first arrive from the reporters, is akin to the MQTT message broker in the UNS. It’s the central hub where all information is initially collected before being processed.
- Sorting and Organizing (Stream Processing): The agency staff who sort and organize these messages, adding missing labels or editing for clarity, represent the stream processing component in the UNS. They ensure that each piece of information is correctly categorized and formatted, much like organizing data into the right topic hierarchy and message schema. Once they have all the proper labels, they go back to the telephone center, where the distribution then starts.
- Distribution to Newspapers (Data Consumers): Different newspapers have different interests, similar to how various applications in the UNS subscribe to specific topics. The New York Times, interested in a broad range of topics, might receive information on the Sydney earthquake, while a specialized IT magazine might only receive tech-related news. The New York Times would have probably subscribed to everything in APAC and below, similar to using a wildcard subscription in a message broker such as
world/apac/#. The IT magazine would have probably subscribed to something likeinformation-technology/#. This reflects how data consumers in the UNS selectively access the data they need. In the telephone center of the news agency, they would for each message look at the labels, and then inform the subscribers of these labels about the related information. - Protocol Converters (Translators): In cases where local reporters don’t speak English or information is in a different format, translators are used. These are like the protocol converters in the UNS, translating different data protocols into a unified event-driven format for ease of integration.
- Open and Flexible Structure: Just like a news agency can quickly adapt to new types of news or local changes in reporting standards, the UNS's open architecture allows for easy integration of new data sources, tools, or technologies without vendor lock-in. This flexibility and openness make it a powerful framework for modern industrial applications. Just to be clear: it is perfectly fine to use vendor-specific software in the UNS, as long as it's a producer or consumer, and not baked into the actual UNS architecture.
Where is the Data Stored in the Unified Namespace?
A common question about the Unified Namespace (UNS) is about data storage. Typically, we observe that the UNS primarily functions as an event-driven architecture (refer to the above definition), but for data storage, additional components like a Historian or an open-source database are added (see also the architecture of the data infrastructure of the UMH). While the UNS does feature message buffering — holding data temporarily until it's received by all consumers — this method is not suitable for storing data over extended periods, such as several years. Message brokers, which are central to the UNS, are not designed for long-term data storage.
To learn about how we at UMH approach the topics of "Visualizing" and "Browsing" the UNS, check out the last chapter. Here's a little spoiler: we add our Management Companion (akin to an agent) to each message broker. This companion continuously monitors the broker, extracts information, and compiles it into a single ISA-95 style tree structure in the Management Console.
The Rise of Unified Namespace on the Internet
Despite some ambiguity in its definition, the Unified Namespace has attracted a significant following. Its growing popularity is marked by the increasing number of members in Walker Reynolds' Discord community (over 5,000 as of September 15, 2023) and mentions in authoritative industry reports, including those by Gartner.
The Unified Namespace (UNS) is seen as a solution to the limitations of the traditional ISA95 Automation Pyramid. It acts as a central hub, gathering real-time data from every layer of the automation pyramid and organizing it in a structured, accessible format. This system uses a message broker at its core, ensuring all data is available in real-time and in a usable form.
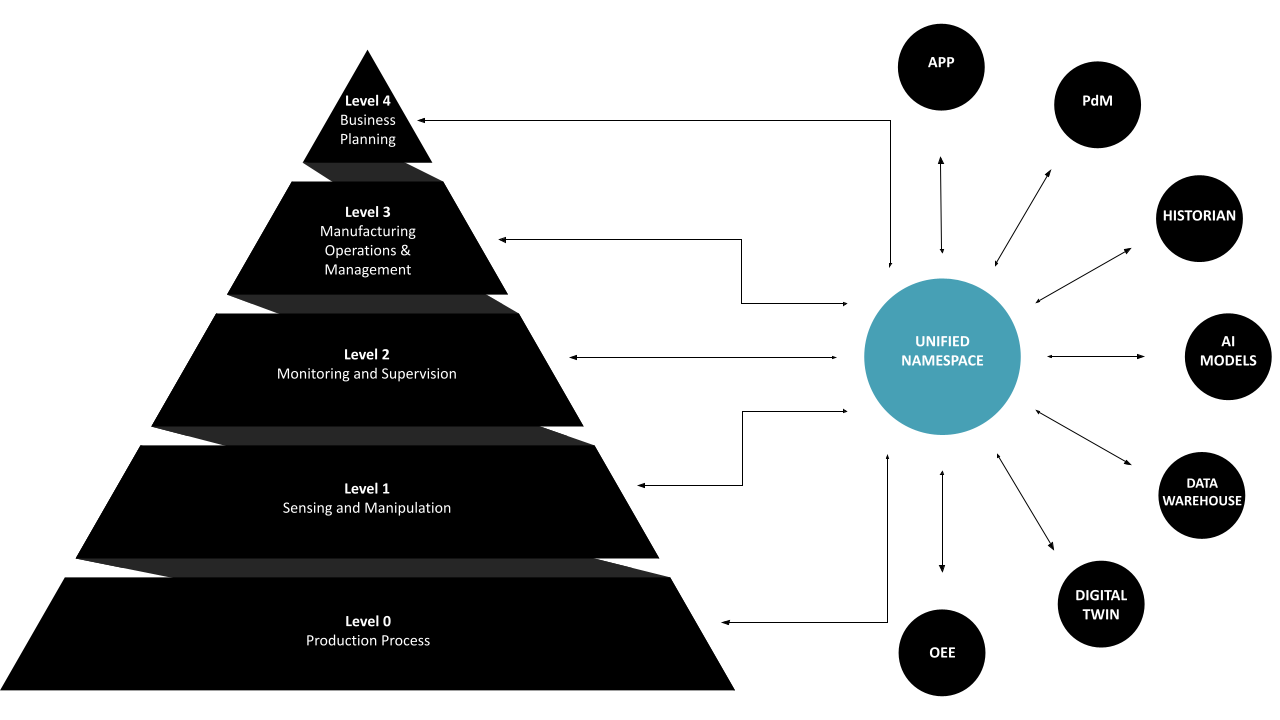
Now, let's explore its practical applications. By sourcing data directly from each layer of the pyramid, UNS facilitates access to high-quality, raw data. This unified data environment greatly simplifies the development of cross-layer applications. For example, a dashboard could simultaneously show MES order information and real-time machine updates such as live temperature and pressure readings, providing invaluable insights to operational staff.
The financial benefits are equally compelling. Integrating new applications with UNS is not only more cost-effective but also less risky. The ease of access to data means new applications can be prototyped quickly and without substantial initial investments. Check out the LinkedIn article from our colleague Denis for some concrete examples.
This is particularly beneficial in regulated industries, like pharmaceuticals, where the introduction of new applications does not necessarily mandate a complete re-qualification of processes, as the foundational structure of the pyramid is maintained.
The deployment of UNS is generally a phased process. It starts with setting up a message broker and connecting a few initial data sources. Once the system's efficiency and effectiveness are established, it can be expanded to include additional data sources, typically driven by the specific requirements of individual use cases.
Understandably, there's some hesitancy and a need for clarity, especially when it comes to gaining trust and explaining this concept to management. The question arises, 'How can I present this idea effectively? Surely, I can't just refer them to a YouTube video from an American YouTuber, right?' This concern is quite common.
I'm not here to falsely claim that the Unified Namespace is widely adopted in its explicit form – that wouldn't be truthful. It is growing in popularity, but in in the bigger picture it is not widely adopted yet.
Similarly, the so-called 'Industrial IoT' platforms and other managed cloud services haven't seen extensive adoption either. Often, when inquiring about real-world deployments of Industrial IoT platforms, you're initially met with marketing gloss and impressive sales presentations. Yet, in my experience, a conversation with the actual shop floor personnel in these 'deployed' environments reveals a different story. They might not have even heard of the solution, or if they have, it's likely been used sparingly, maybe a few times months ago.
But let's not stray too far off course. Instead of relying on fancy slides, I offer something more substantial: the concept of the Unified Namespace is grounded in core IT principles. In fact, major IT companies like Google, Facebook, and Amazon are already utilizing similar concepts at scale. It's highly probable that your own organization is employing this approach too, albeit under different names.
IT / OT Integration Platform for Industrial DataOps
Connect all your machines and systems with our Open-Source IT/OT Integration Platform to make all shop-floor data accessible at a single point.