


It does not matter how you spin it, you will always land up with a Unified Namespace. In various industries beyond manufacturing, it's known by several names:
- Publish-Subscribe, often abbreviated as Pub-Sub
- Event-driven Architecture
- Event-Streaming
- Message Broker
- Protocols like MQTT, AMQP, Kafka, and more
It is almost everywhere where large amounts of data needs to be processed from large amounts of producers/consumers. In this chapter, I plan to delve deeply into two specific perspectives:
- “Unified Namespace” is one fundamental principle on how to build larger applications. This perspective was previously discussed in our article “Comparing MQTT Brokers for the Industrial IoT”.
- “Unified Namespace” is done whenever companies connect to the cloud. This perspective was previously discussed in our article “Integrating the Unified Namespace into Your Enterprise Architecture: An Architect's Guide.”
“Unified Namespace” is one fundamental principle on how to build larger applications
I've touched upon this topic before, but it found an unusual spot at the start of an article comparing MQTT brokers. Let's revisit it briefly:
In "Designing Data-Intensive Applications", Martin Kleppmann, a researcher at the University of Cambridge with a remarkable background in companies like LinkedIn, explores the foundational elements of data-intensive applications. The book has garnered high praise from notable industry experts such as the CTO of Microsoft, Principal Engineers at Amazon Web Services or Jay Kreps, the creator of Apache Kafka and CEO of Confluent.
Kleppmann identifies four essential building blocks that form the core of data-intensive applications:
- Long-lived databases to store data
- Short-lived caches to speed up expensive operations
- Stream processing blocks to continuously process and share data
- Batch processing blocks to periodically process batches of data
To connect these building blocks, there are three common architecture approaches:
- Dataflow through databases
- Dataflow through service calls
- Dataflow through asynchronous message passing
Dataflow through Databases
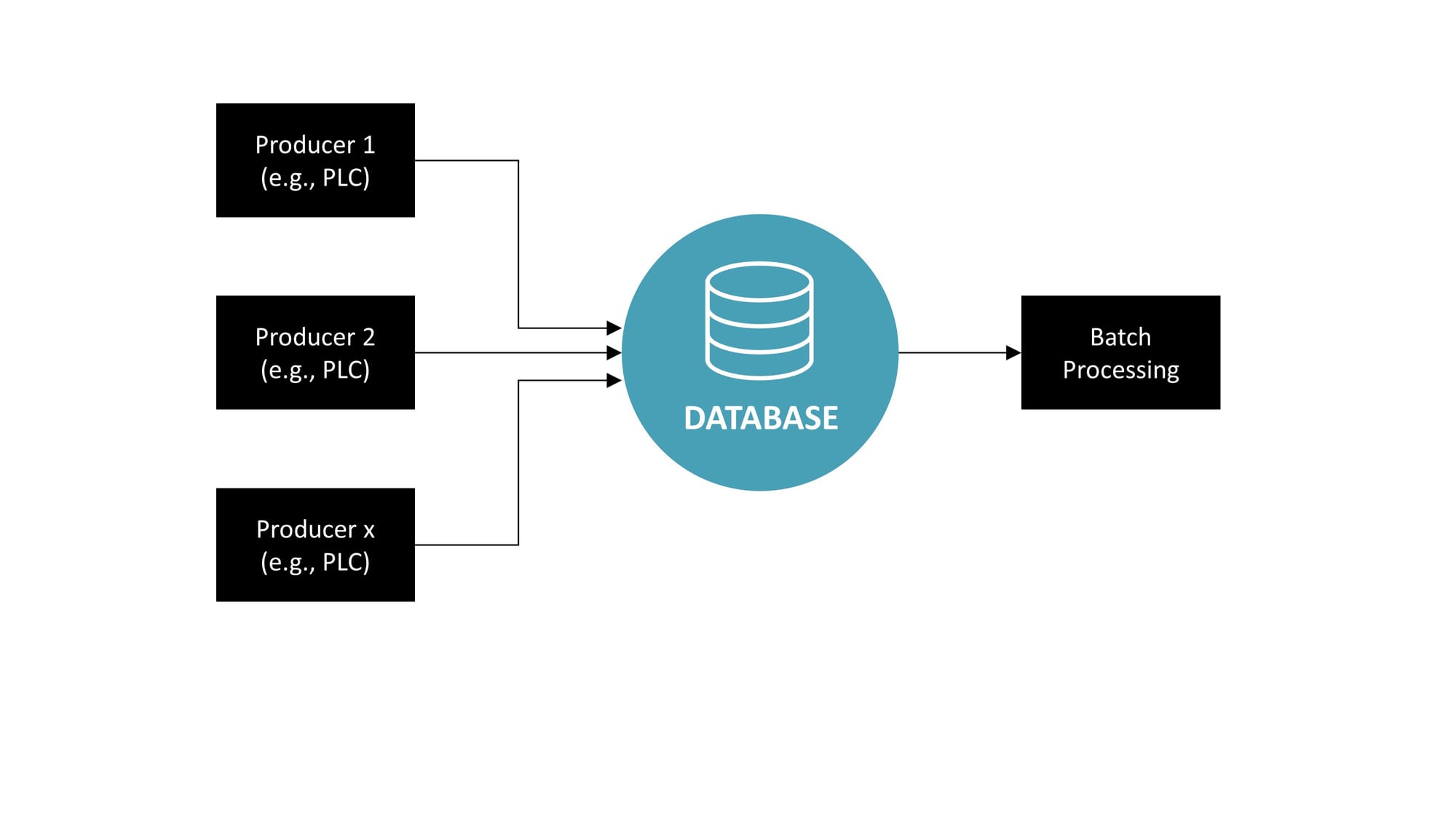
In this architectural approach, various components that produce data, commonly referred to as Producers (like PLCs, MES, or ERP systems), transmit data directly into a centralized database. This method is straightforward and orderly, with each producer sending its data to a single collection point for storage. From this database, the information can then be used for batch processing, which handles large volumes of data in scheduled operations. However, this setup doesn't support real-time stream processing — the ability to analyze and act upon data as it's generated. This is because traditional databases are designed for storage and retrieval, not for the dynamic, ongoing analysis that streaming requires. Therefore, while this model is efficient for historical data analysis and reporting, it lacks the capacity for immediate, continuous insights that modern data-driven operations often necessitate.
Dataflow through Service Calls
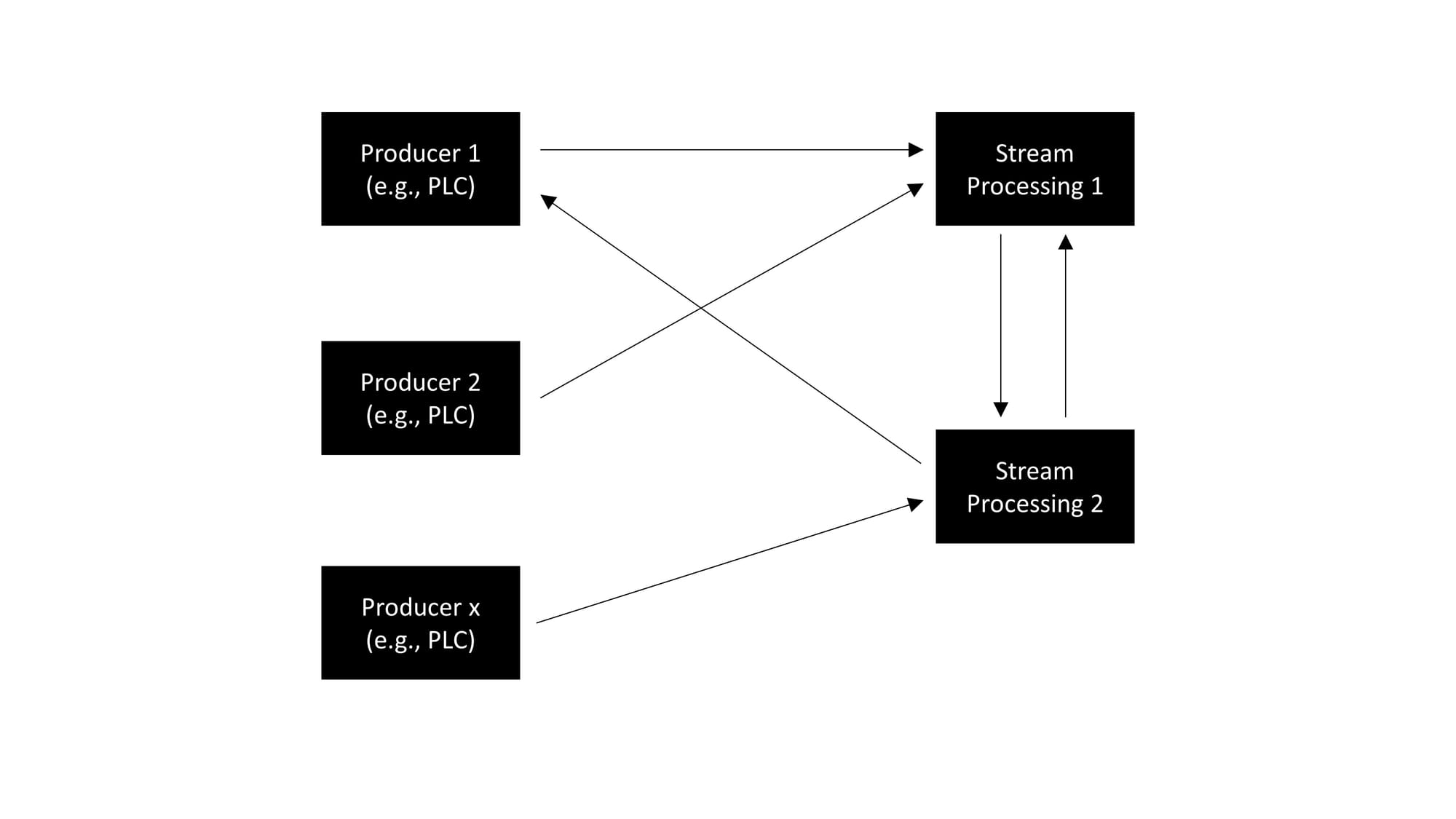
In this architecture, data producers such as PLCs are directly linked to various stream processing services. Each producer might send data to multiple services, and each service may receive data from multiple producers, creating a network of connections. This direct interaction enables real-time processing of data streams, as each service processes the incoming data as it arrives.
However, as the system scales and more producers and stream processors are added, the complexity of connections can grow exponentially. This expansion can result in a tangled web of interactions, commonly known as spaghetti diagrams. Such complexity makes the system difficult to maintain, understand, and modify, as every service is interconnected with many others in a non-linear fashion. Without careful design and documentation, this can lead to a fragile system architecture that is hard to debug and adapt to changes.
Dataflow through asynchronous message passing
The third approach, "asynchronous message passing", introduces a fifth building block: the message broker. This is also sometimes called as “Pub/Sub” or “Event-driven Architecture”.
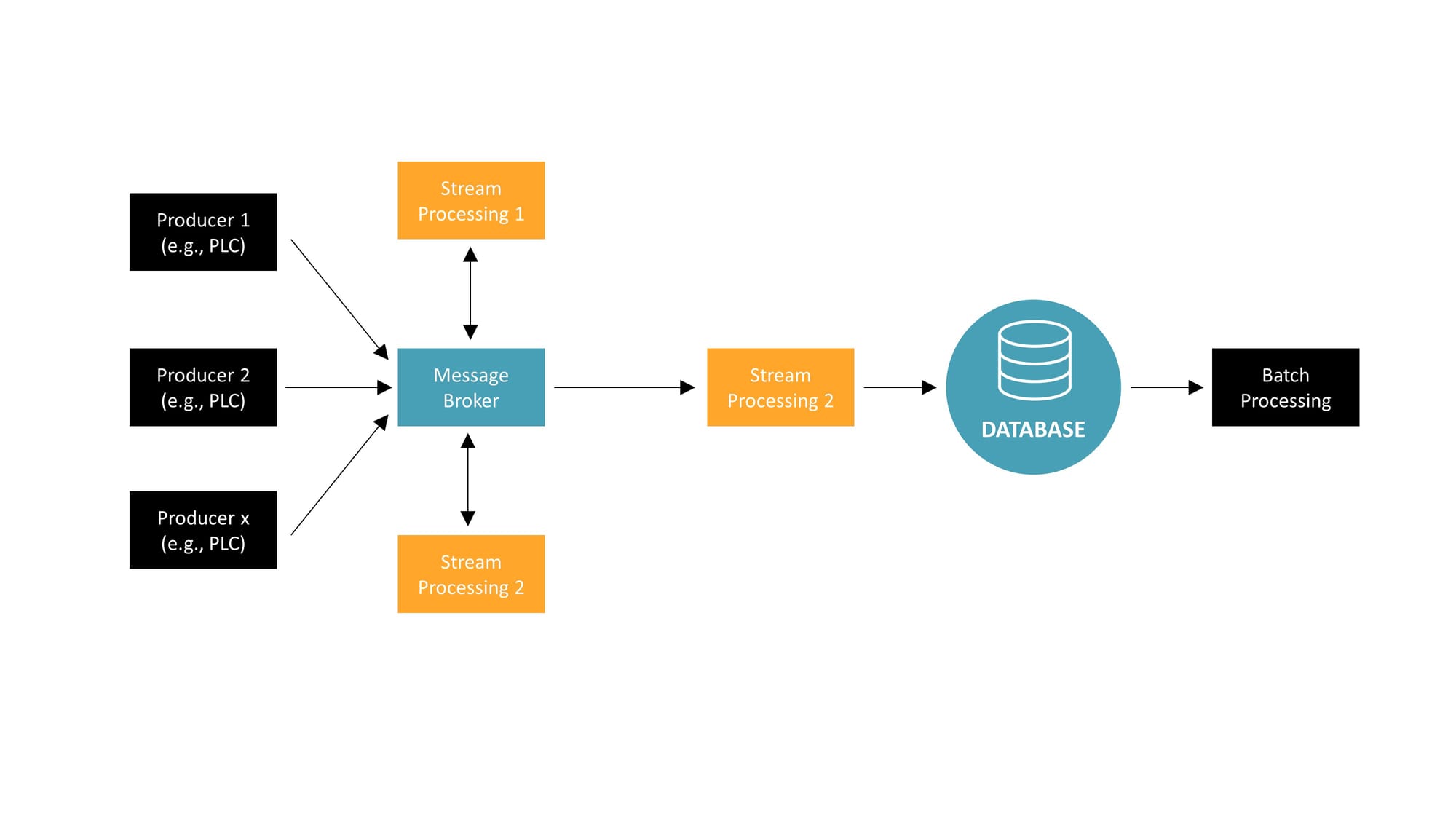
This architectural model introduces a message broker as the central hub for data communication, which greatly simplifies the data flow between producers and consumers. In the diagram, we see multiple data producers, such as PLCs, sending their data to a message broker. The message broker then distributes this data to various stream processing units based on subscription topics.
Each stream processing unit handles its specific data processing tasks in real time. For example, Stream Processing 1 might handle real-time analytics, while Stream Processing 2 could deal with real-time monitoring. The processed data from these streams can then be funneled into a database for persistence. Additionally, there's a batch processing unit shown, which could be used for heavier, less time-sensitive computations that can be run on a schedule.
This setup allows for a cleaner separation of concerns and easier scalability. As new producers or consumers are added, they can simply connect to the message broker without affecting the existing system structure. This avoids the intricate and hard-to-maintain web of connections that characterize the "spaghetti diagrams" seen in direct service call architectures. Moreover, the message broker facilitates a more efficient data flow management, ensuring that data is processed in a timely manner and only sent to the parts of the system that require it.
In manufacturing applications, which often run for 10-20 years, it is important to have the ability to easily plug in new components or remove existing ones. This helps prevent spaghetti diagrams and allows for real-time data processing. While introducing an additional building block like the message broker into the architecture might seem like a disadvantage due to its complexity, in the manufacturing sector, the benefits far outweigh these concerns. The ability to process data in real time and adapt to evolving technological needs makes this approach particularly valuable.
Does that not sound familiar? Yes, it is very similar to the concept of a Unified Namespace.
But we can go further:
“Unified Namespace” is done whenever companies connect to the cloud
In a previous article I already discussed this as well. The UNS is really an application of a battle-tested IT-architecture that already enjoys widespread adoption in sectors that are more advanced in IT than the manufacturing industry (banking, startups, etc.). Let's take another, more summarized, look at this explanation:
Working with data is not something new to manufacturing and that requires new tools and techniques, it is well known in various other fields such as banking, retail, or online platforms (think of LinkedIn, Amazon, etc.). So let’s look at the old, established, tried-and-tested technology because it guarantees stability. No need for fancy stuff.
Let’s start by distinguishing between two types of databases: OLTP and OLAP. OLTP databases are like the diligent record-keepers of daily transactions, ensuring that data is always current for frontline workers. OLAP databases, however, are used by business analysts to dig deep into data history and extract strategic insights.
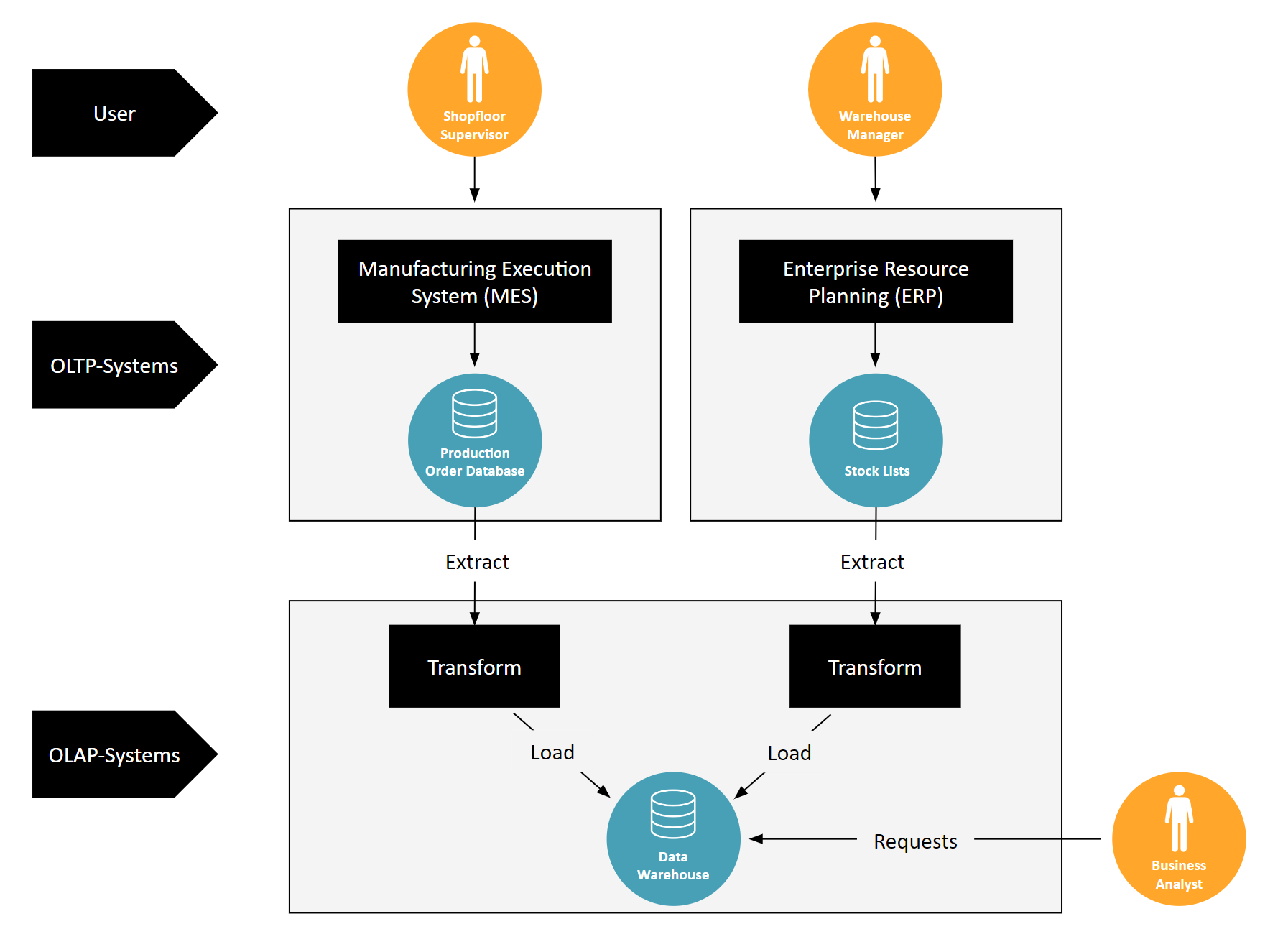
The connection between OLTP and OLAP systems traditionally happens through an ETL process. This is where data is extracted from OLTP databases, transformed for analysis, and then loaded into OLAP systems. Think of the image with the Manufacturing Execution System (MES) and the Enterprise Resource Planning (ERP) system: data flows from production orders and stock lists into the ETL process, ultimately landing in a Data Warehouse for business analysts to use.
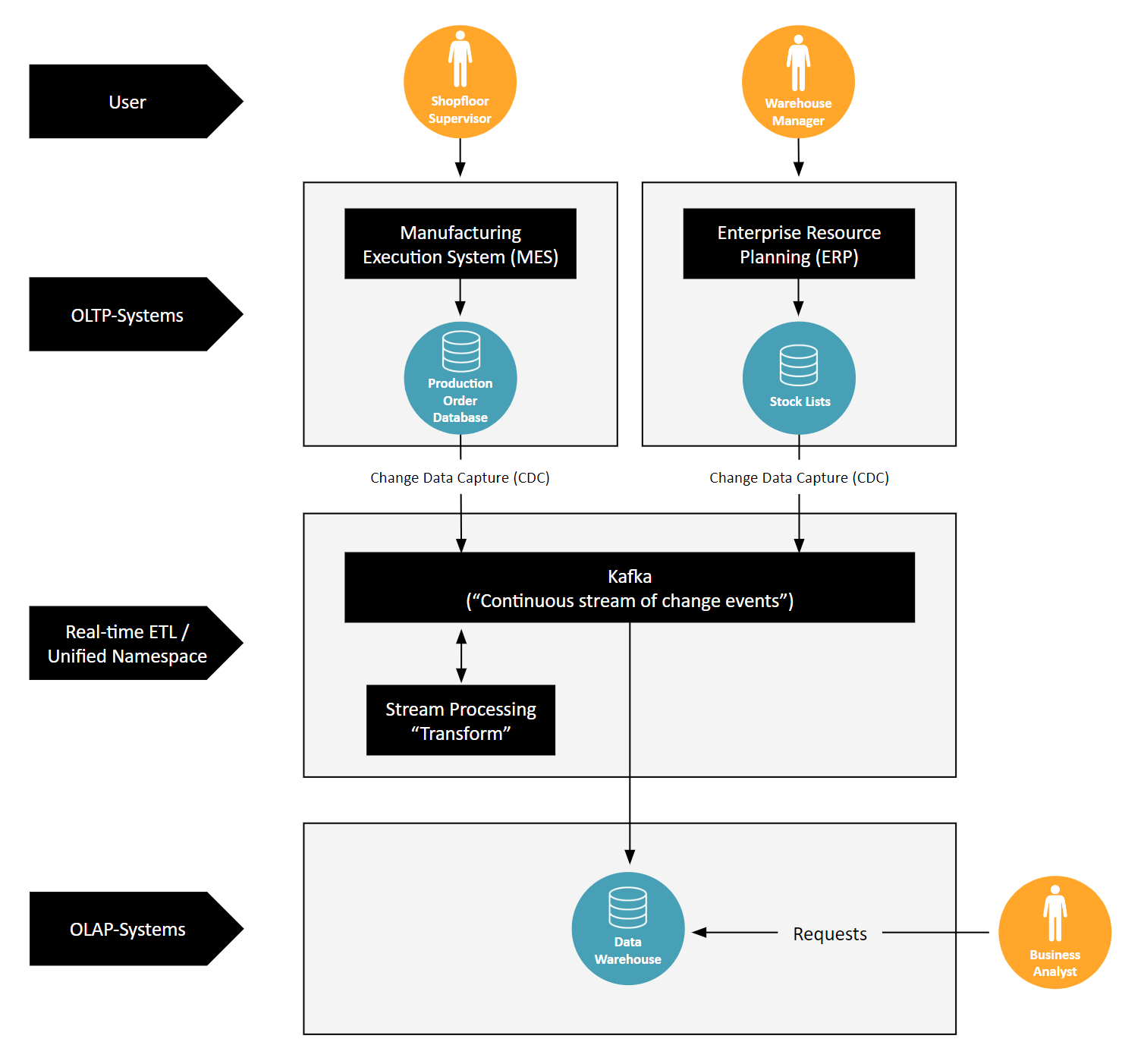
In the modern data landscape, however, there's a push for real-time data processing. That's where the second image with Kafka comes into play. Kafka enables a shift from batch processing to streaming data in real time. Using Change Data Capture (CDC), it captures changes as they occur in OLTP systems. This data is then instantly transformed and loaded into OLAP systems, allowing for immediate analytical access.
This process mirrors the Unified Namespace — a 'continuous stream of change information.' By adopting Kafka and streaming data in real time, companies effectively create a UNS when they connect to the Data Warehouse (typically also just called "cloud"). This means that all data, as it is generated, is immediately available across the enterprise, breaking down barriers and enabling a unified, agile approach to data management.
As we conclude this exploration, it becomes evident that regardless of the terminology—be it Pub-Sub, Event-driven Architecture, Event-Streaming, or Message Broker—the core concept of a Unified Namespace is universally recognized as a vital component in the architecture of data-intensive applications. This principle holds true across various industries, not limited to manufacturing.


