


In the fast-paced Industry 4.0 era, understanding the full spectrum of data models is crucial. Although many guides claim to provide "complete" data models for Industry 4.0, a closer examination often reveals gaps in their coverage. Data does not exist solely in an OPC-UA server. It also resides in message brokers, databases, APIs, and data lakes. Each of these tech-stack components has certain standards or best practices that should be adhered to. For example, there are standards defining the exact tag names of each machine, and comprehensive books have been written on the optimal ways to store and model data in relational / SQL databases.
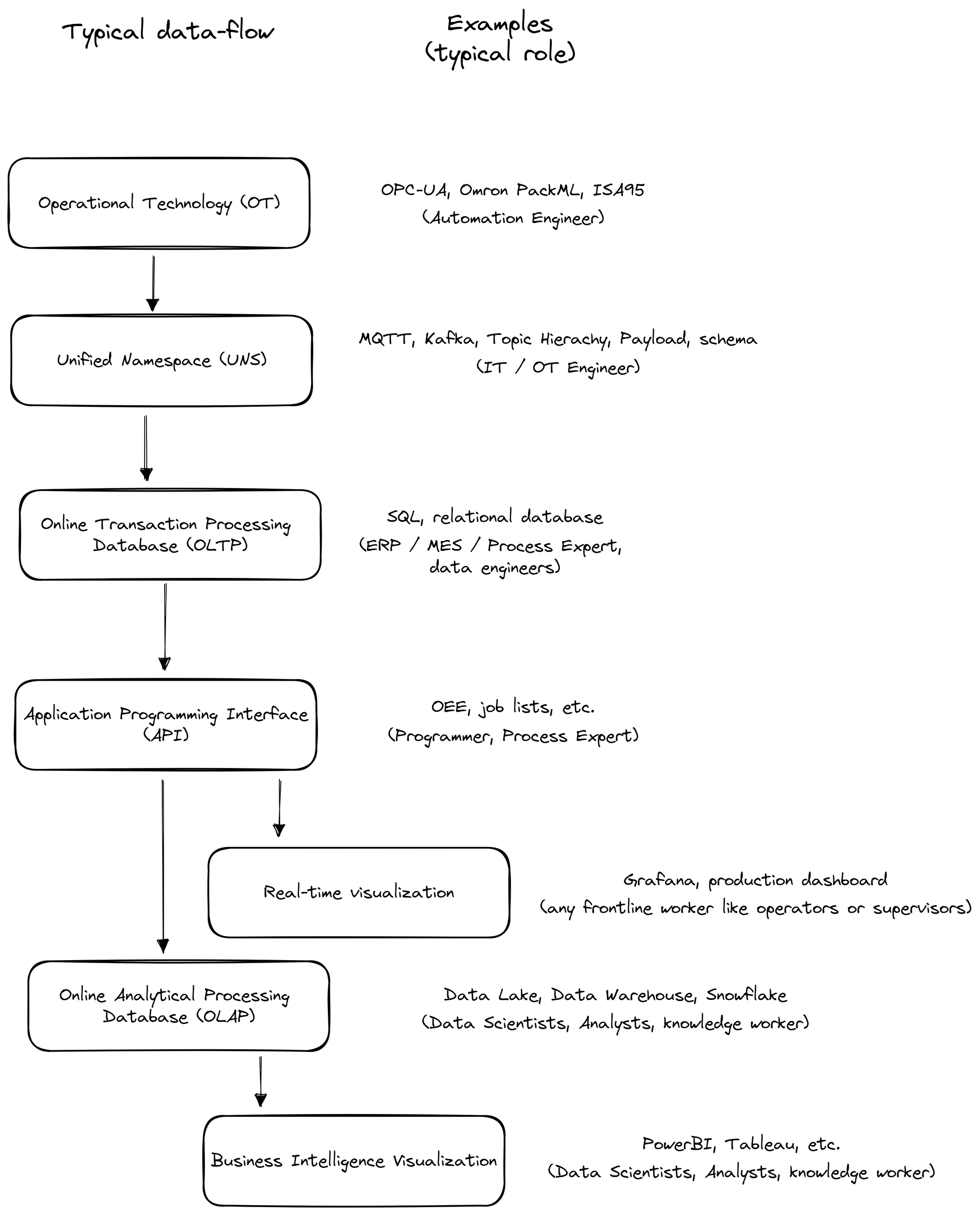
This guide will delve into a UNS-based architecture that incorporates the extraction of data from the Operational Technology (OT) side, its transmission into a message broker, storage into a database, retrieval from an API, and further storage in a data lake for data scientists.
The following chapters will cover:
Understanding the Main Archetypes of Data in Manufacturing
In this chapter, we'll delve into the main archetypes of data commonly found in the manufacturing industry: relational data, time-series data, and semi-structured or unstructured data.
A) Data Modeling in Operational Technology (OT): From ISA-95 over EUROMAP to OPC-UA
At the heart of data generation in the manufacturing process lie OT data models. We divide these models into two types: Specific Operational Models and Generalized Abstracted Data Models.
Specific Operational Models serve as a foundation for understanding the operational processes, detailing potential values and tags. We discuss a few examples, such as Weihenstephan Standards (WS) 09.01, Omron PackML, EUROMAP 84, OPC 30060, and VDMA 40502.
Contrarily, Generalized Abstracted Data Models offer a broad overview of the entire production process. They're typically used alongside Specific Operational Models for a complete understanding. Examples include: OPC-UA and Asset Administration Shells (AAS).
Relational databases present in operational technology can also contribute to a Unified Namespace (UNS) model, which we will explore in more detail in later chapters. Typically, process and OT engineers define OT systems and data models.
B) Data Modeling in the Unified Namespace (UNS): From Topic Hierachies over Payload Schemas to MQTT/Kafka
From the OT stage, data usually moves into a UNS. The UNS model, in conjunction with the event-driven architecture schema and a message broker, organizes data efficiently for real-time events. It ensures smooth communication and information exchange by maintaining a clear topic structure and defining payload attributes. The strategy for data transmission varies based on the data categories - relational, time-series, and semi-structured or unstructured data. IT / OT engineers typically undertake the implementation of these data models.
C) Data Modeling in Online Transaction Processing Databases (OLTP):
Data typically flows from a UNS into an SQL-based database, used by frontline workers on the shop floor. OLTP systems form a cornerstone in manufacturing environments, offering immediate access to crucial data, such as job lists and employee login records. Five best practices guide the data modeling process for OLTP systems, focusing on principles of efficiency and data normalization.
- Identify Key Entities and Relationships: Begin with core entities like jobs, shifts, products, and employees and their interrelations (use ISA-95 as starting point).
- Normalize the Data Model: Aim for the third normal form (3NF) to enhance data integrity and optimize write operations.
- Optimize for Performance: Design your data model for fast data access, with careful selection of primary keys and indexes on frequently accessed columns.
- Ensure Data Integrity: Maintain data integrity by leveraging database features like primary keys, foreign keys, unique constraints, and check constraints.
- Plan for Growth: Design your data model with growth in mind, as your business and data evolve.
Usually, MES/ERP or process experts, along with IT specialists, define OLTP databases.
D) Data Modeling in Application Programming Interfaces (API):
APIs, which often sit atop OLTP databases, process the raw data into more meaningful, accessible information. This processed data can then be visualized using tools like Grafana, facilitating easy interpretation by operators or supervisors. Process experts and programmers typically define these.
E) Data Modeling in Online Analytical Processing Databases (OLAP):
Data from APIs is typically transferred at daily intervals into the enterprise data lake. OLAP and Data Lakes are designed for intricate data analysis, facilitating informed decision-making. These tools are utilized by data scientists, business analysts, and others to investigate more extensive aspects like supply chains, logistics, and customer-to-product flows.
F) Data Modeling Overall:
The unified data model ensures that data analysis insights can be converted back into actionable information in the OT domain. By retaining a level of abstraction for OT interpretation, the original meaning of the data remains intact throughout its journey.
The subsequent chapters will delve deeper into each of these data models, providing a thorough understanding of their roles and functions within manufacturing architectures.
Throughout this guide, we'll explore the theory behind each of these models and how they are implemented at the United Manufacturing Hub. Remember, this is a journey, and your feedback is always appreciated. The subsequent chapters will dive deeper into each data model, providing a thorough understanding of their roles and functions within manufacturing architectures. Welcome to the journey.


